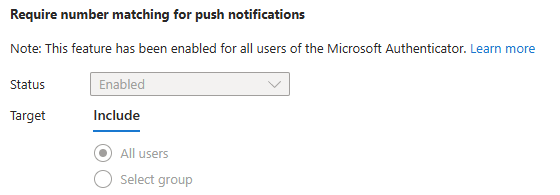
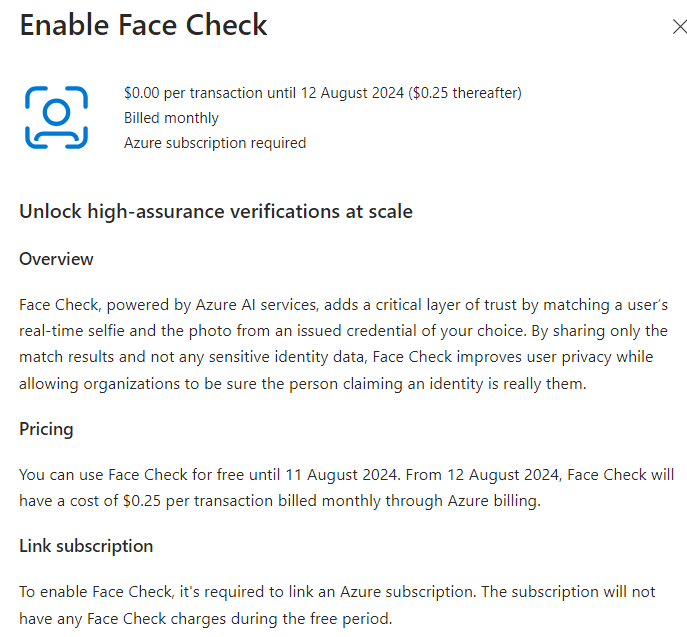
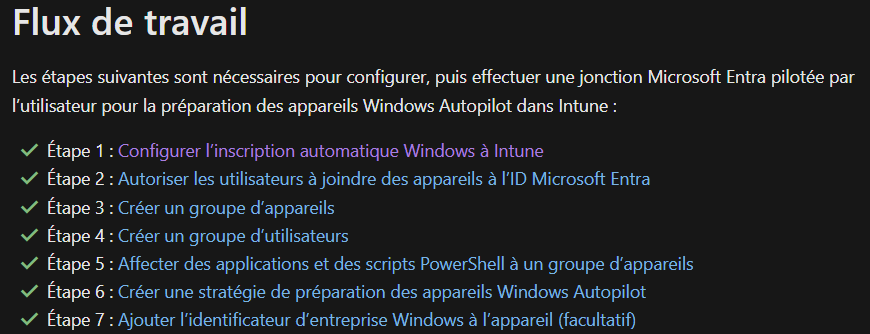
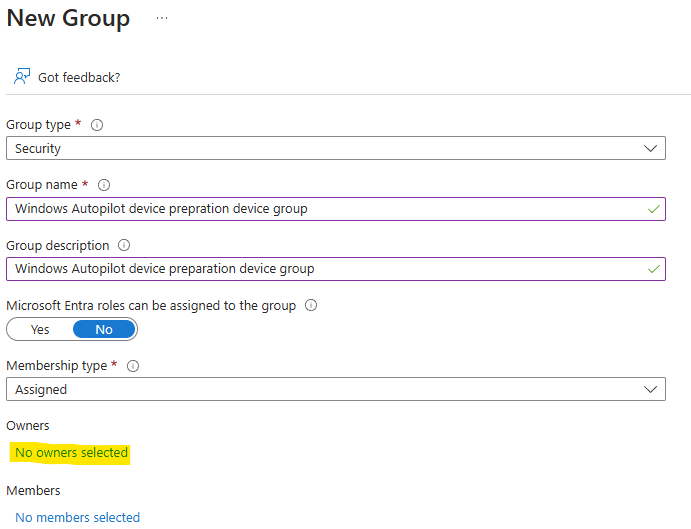
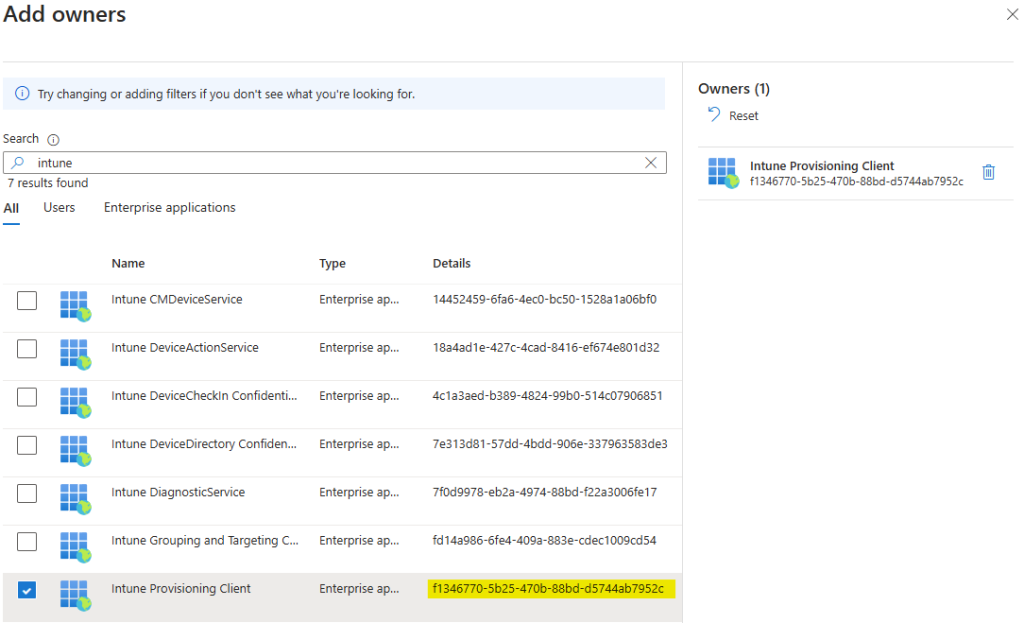
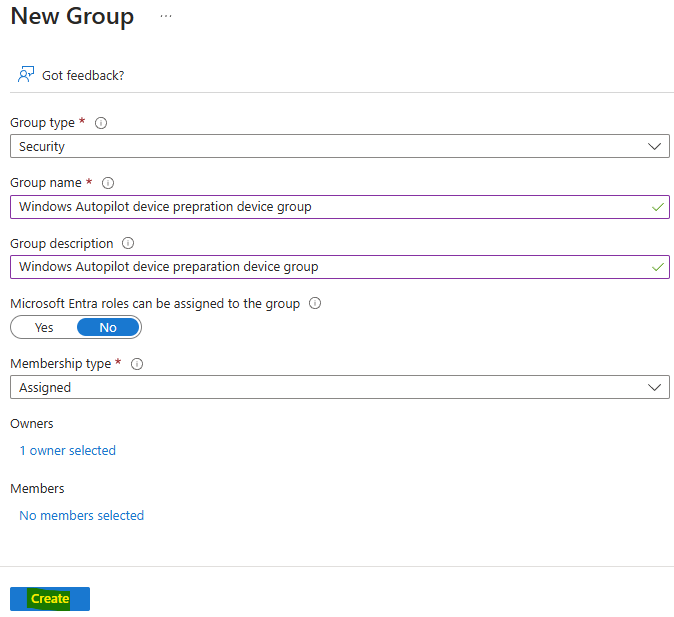
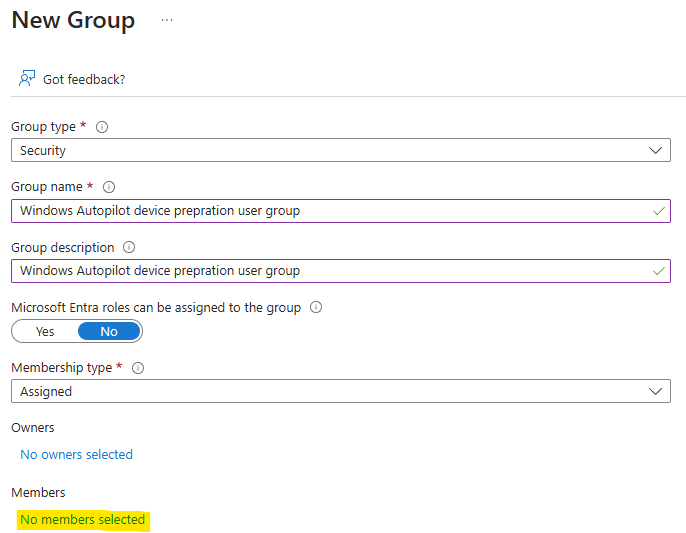
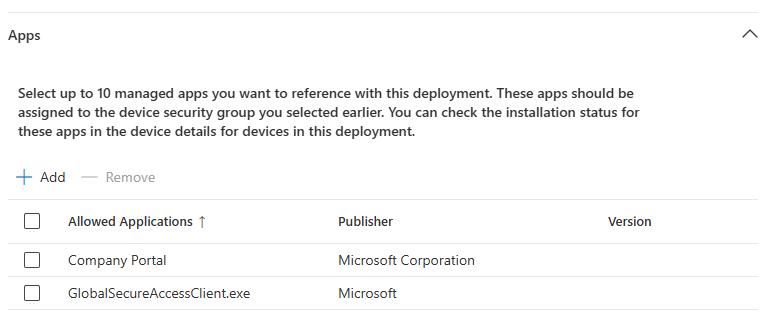
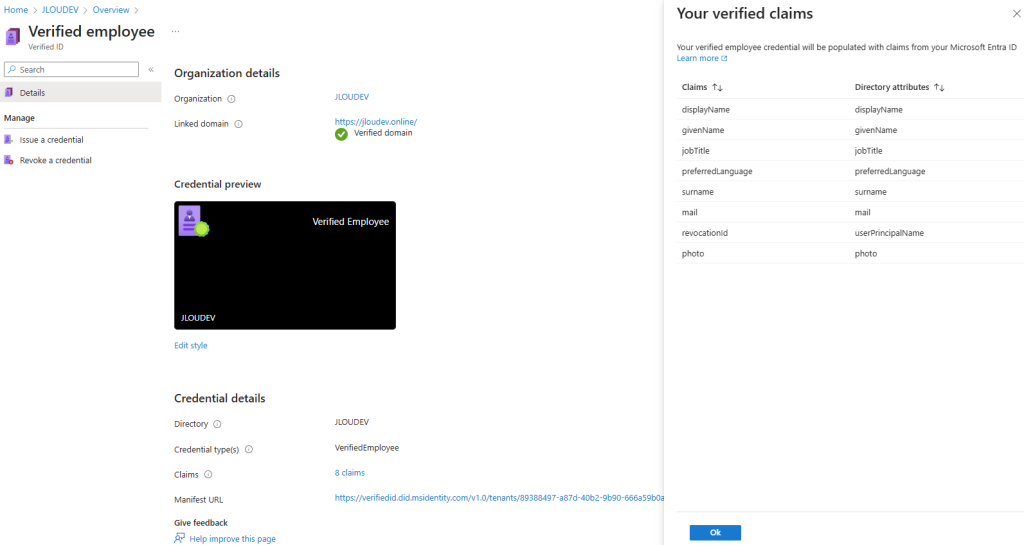
Comme tous les services Cloud, Azure Bastion continue d’évoluer et s’améliorer via l’ajout de nouvelles fonctionnalités très pratiques. Au travers de cet article, nous prendrons le temps de refaire un tour du service et de ses changements dans sa gamme et ses fonctionnalités, comme l’enregistrement automatique ou l’accès 100% privé.

Cet article n’est pas le premier à parler d’Azure Bastion sur ce blog, voici un lien vers celui écrit en 2023. Depuis cette date, le produit a subi quelques changements que nous aborderons ici.
Qu’est-ce qu’Azure Bastion ?
Côté Microsoft, le but de ce service de jump n’est pas changé :
Azure Bastion est un service PaaS entièrement managé que vous approvisionnez pour vous connecter en toute sécurité aux machines virtuelles via une adresse IP privée. Il fournit une connectivité RDP/SSH sécurisée et fluide à vos machines virtuelles, directement au travers du protocole TLS depuis le Portail Azure ou via un SSH natif ou un client RDP déjà installé sur votre ordinateur local. Quand vous vous connectez via Azure Bastion, vos machines virtuelles n’ont pas besoin d’adresse IP publique, d’agent ou de logiciel client spécial.
Azure Bastion est donc toujours un service de jump pour accéder aux machines virtuelles sur Azure, que celles-ci soient sous Windows ou Linux.
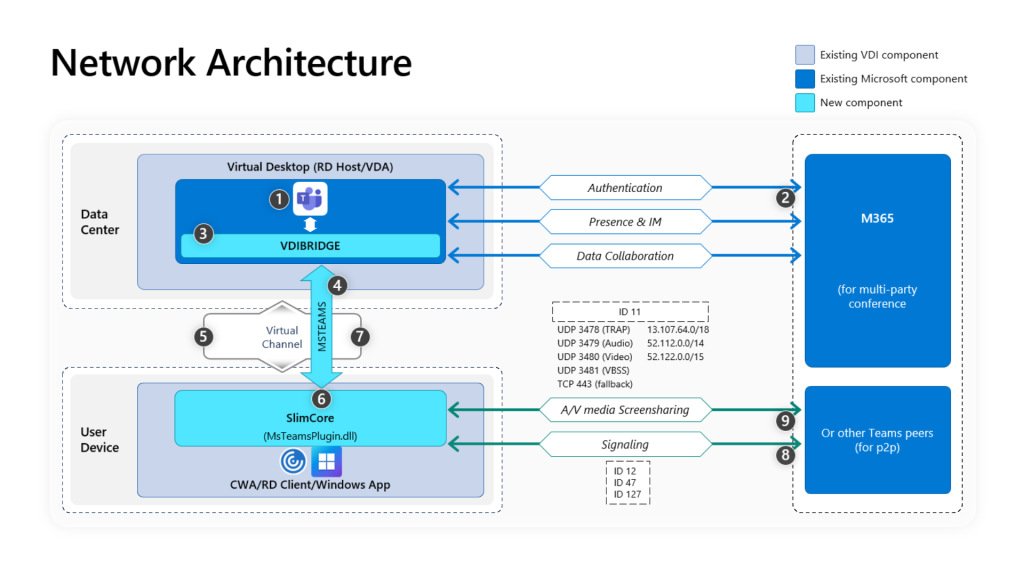
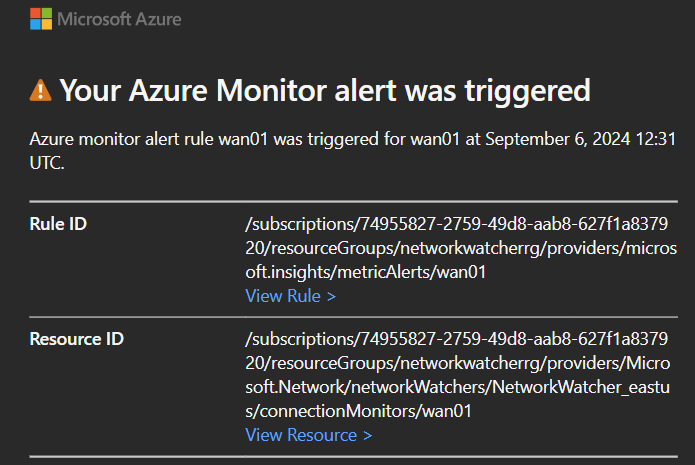
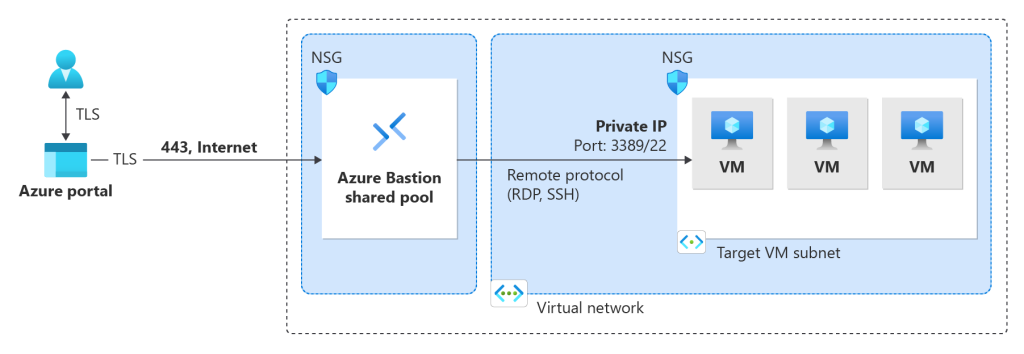
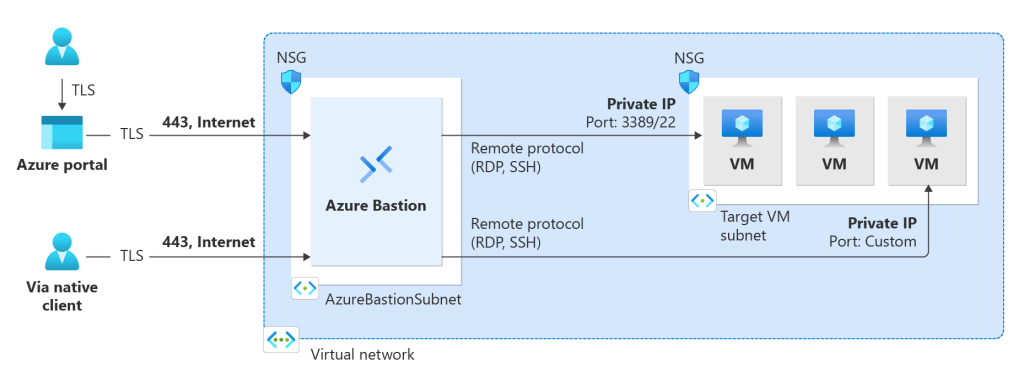
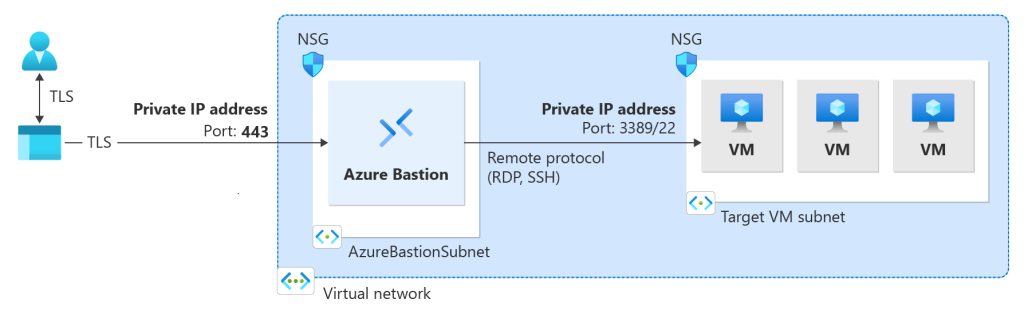
Le schéma ci-dessous nous montre le tunnel d’accès créé entre Azure Bastion et l’utilisateur initiateur (via une connexion inversée) grâce au protocole TLS :
Bastion fournit une connectivité RDP et SSH sécurisée à toutes les machines virtuelles du réseau virtuel pour lequel il est approvisionné. Azure Bastion protège vos machines virtuelles contre l’exposition des ports RDP/SSH au monde extérieur, tout en fournissant un accès sécurisé à l’aide de RDP/SSH.
J’ai également reposté la vidéo dédiée à Azure Bastion en français juste ici :
Quel est le principal point fort d’Azure Bastion ?
Un seul mot me vient tout de suite en tête : SECURITE.
Comme tout service de jump, Azure Bastion devient de facto la ressource exposée de votre infrastructure Cloud. Dans les faits, ce dernier intègre des fonctions de pare-feu et des mesures périmétriques de sécurité.
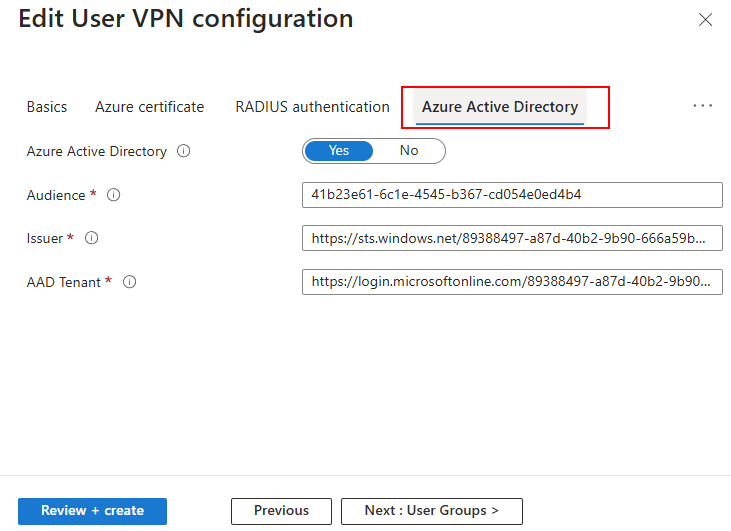
De plus, l’accès au service depuis le portail Azure apporte la couche de pré-authentification d’Azure AD. Celui-ci profite alors de toutes ses mesures de sécurité, comme l’Accès conditionnel, la gestion des droits RBAC, etc …
L’approche d’une connexion sécurisée via TLS permet de s’affranchir de règles sécurités lourdes.
Enfin, Azure Bastion mettra tout le monde d’accord grâce au retrait des adresses IP publiques sur vos VMs Azure, car la connexion RDP/SSH entre Bastion et votre machine virtuelle se fera via le réseau virtuel privé Azure, donc grâce et uniquement par son adresse IP privée.
Pour y voir plus clair, Microsoft met à disposition un tableau de ses principaux avantages :
| Avantage | Description |
|---|---|
| RDP et SSH par le biais du portail Azure | Vous pouvez accéder directement à la session RDP et SSH directement dans le portail Azure via une expérience fluide en un seul clic. |
| Session à distance sur TLS et traversée de pare-feu pour RDP/SSH | Azure Bastion utilise un client web basé sur HTML5 qui est automatiquement diffusé sur votre appareil local. Votre session RDP/SSH utilise TLS sur le port 443. Le trafic peut ainsi traverser les pare-feu de façon plus sécurisée. Bastion prend en charge TLS 1.2. Les versions antérieures de TLS ne sont pas prises en charge. |
| Aucune adresse IP publique n’est nécessaire sur la machine virtuelle Azure. | Azure Bastion ouvre la connexion RDP/SSH à votre machine virtuelle Azure en utilisant l’adresse IP privée sur votre machine virtuelle. Vous n’avez pas besoin d’une adresse IP publique sur votre machine virtuelle. |
| Aucune contrainte liée à la gestion des groupes de sécurité réseau (NSG) | Vous n’avez pas besoin d’appliquer des groupes de sécurité réseau sur le sous-réseau Azure Bastion. Comme Azure Bastion se connecte à vos machines virtuelles par le biais d’une adresse IP privée, vous pouvez configurer vos groupes de sécurité réseau pour autoriser RDP/SSH depuis Azure Bastion uniquement. Vous n’avez plus à gérer les groupes de sécurité réseau chaque fois que vous devez vous connecter de manière sécurisée à vos machines virtuelles. Pour plus d’informations sur les groupes de sécurité réseau, consultez Groupes de sécurité réseau. |
| Vous n’avez pas besoin de gérer un hôte Bastion distinct sur une machine virtuelle | Azure Bastion est un service PaaS de plateforme entièrement géré d’Azure, renforcé en interne pour vous fournir une connectivité RDP/SSH sécurisée. |
| Protection contre l’analyse des ports | Vos machines virtuelles sont protégées contre l’analyse des ports par des utilisateurs malveillants, car vous n’avez pas besoin de les exposer à Internet. |
| Renforcement de la sécurité à un seul endroit | Azure Bastion résidant au périmètre de votre réseau virtuel, vous n’avez pas à vous soucier du durcissement de la sécurité de chacune des machines virtuelles de votre réseau virtuel. |
| Protection contre les exploits zéro-day | La plateforme Azure protège contre les exploits du jour zéro en assurant une sécurité durcie permanente et à jour pour Azure Bastion. |
Mais combien coûte Azure Bastion ?
C’est à partir d’ici que les choses ont changé depuis mon dernier article. Il existe maintenant 4 SKUs disponibles pour Azure Bastion :
- Développeur
- Basic
- Standard
- Premium
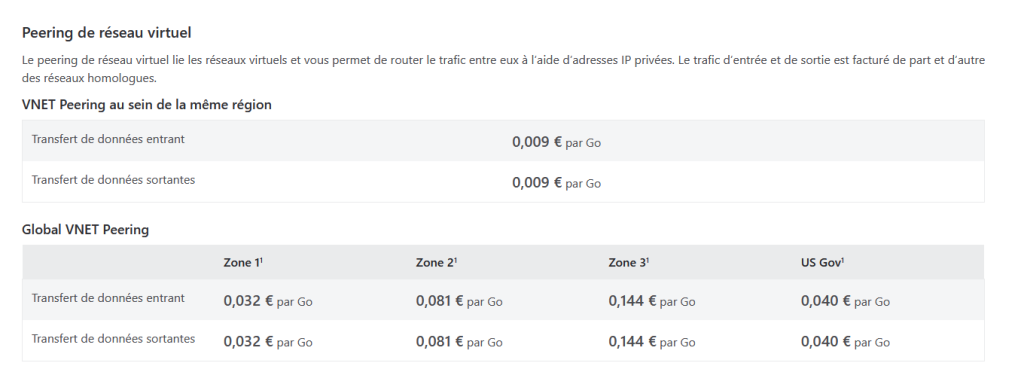
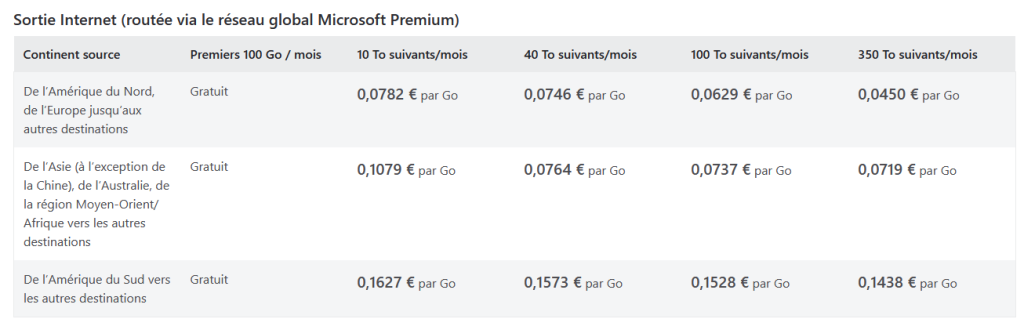
Côté tarif, Microsoft met à disposition une table des tarif d’Azure Bastion sur cette page :
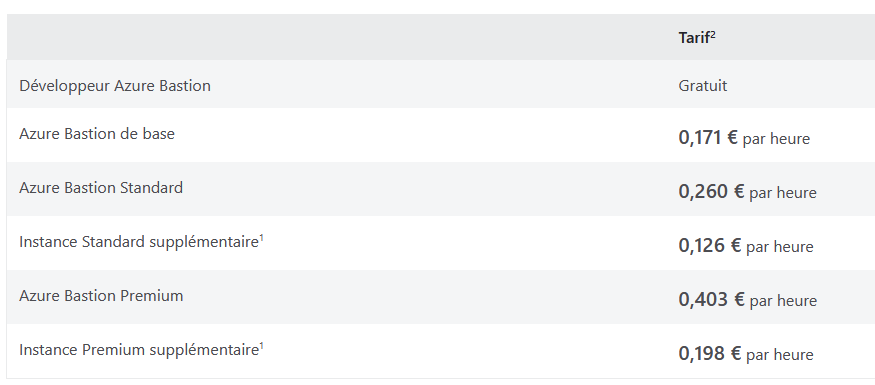
Pour bien se rendre compte des écarts de prix, cela donne les tarifs mensuels suivants :

Comme indiqué au-dessus, Azure Bastion en version Développeur est gratuit, mais votre accès unique repose alors sur une instance partagée d’Azure Bastion :
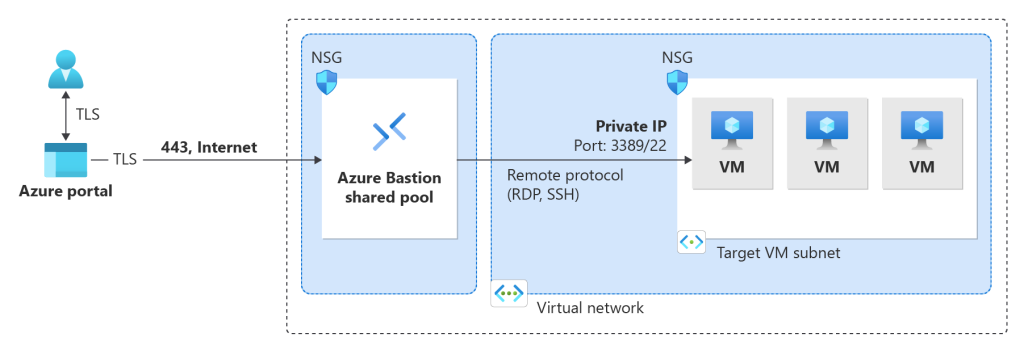
Pour les autres SKUs, Microsoft le dit et je vous le confirme : Azure Bastion est facturé dès que ce dernier est déployé peu importe son utilisation :
Azure Bastion est facturée toutes les heures à partir du moment où la ressource est déployée jusqu’à sa suppression, quelle que soit l’utilisation des données sortantes. La tarification horaire est basée sur la référence SKU sélectionnée, le nombre d’unités d’échelle configurées et les taux de transfert de données.
Quel SKU choisir pour Azure Bastion ?
Les fonctionnalités détermineront le SKU le plus adapté à votre besoin :
| Fonctionnalité | Référence SKU Développeur | Référence De base | Référence Standard | SKU Premium |
|---|---|---|---|---|
| Se connecter pour cibler les machines virtuelles dans les mêmes réseaux virtuels | Oui | Oui | Oui | Oui |
| Se connecter pour cibler les machines virtuelles dans les réseaux virtuels appairés | Non | Oui | Oui | Oui |
| Prise en charge de connexions simultanées | Non | Oui | Oui | Oui |
| Accéder aux clés privées des machines virtuelles Linux dans Azure Key Vault (AKV) | Non | Oui | Oui | Oui |
| Se connecter à une machine virtuelle Linux avec SSH | Oui | Oui | Oui | Oui |
| Se connecter à une machine virtuelle Windows avec RDP | Oui | Oui | Oui | Oui |
| Se connecter à une machine virtuelle Linux avec RDP | No | Non | Oui | Oui |
| Se connecter à une machine virtuelle Windows avec SSH | No | Non | Oui | Oui |
| Spécifier le port d’entrée personnalisé | No | Non | Oui | Oui |
| Se connecter à des machines virtuelles à l’aide de Azure CLI | No | Non | Oui | Oui |
| Mise à l’échelle de l’hôte | No | Non | Oui | Oui |
| Charger ou télécharger des fichiers | No | Non | Oui | Oui |
| Authentification Kerberos | Non | Oui | Oui | Oui |
| Lien partageable | No | Non | Oui | Oui |
| Se connecter aux machines virtuelles via une adresse IP | No | Non | Oui | Oui |
Note : Gardez en tête que pour vous pouvez monter en gamme le SKU de votre Azure Bastion, mais descendre vous sera impossible.
Comment mettre en place Azure Bastion ?
Rien de plus simple, quelques clics suffisent pour déployer Azure Bastion.
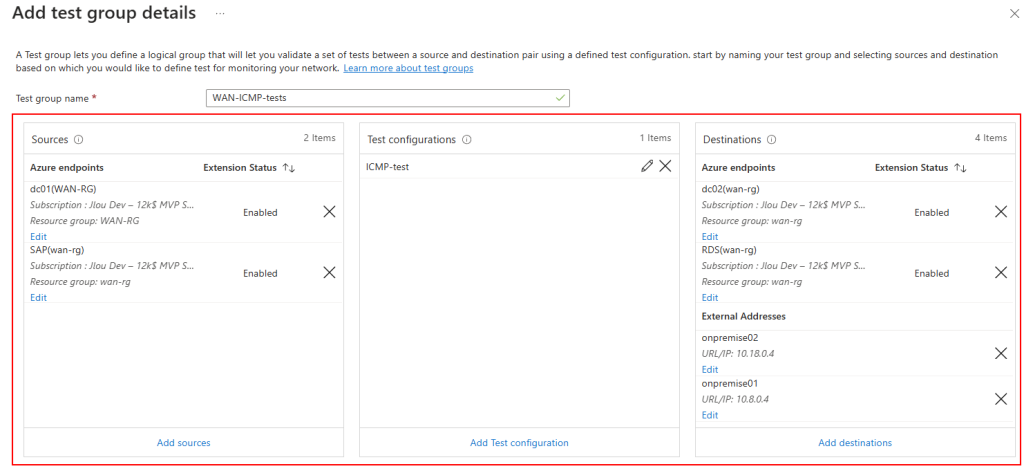
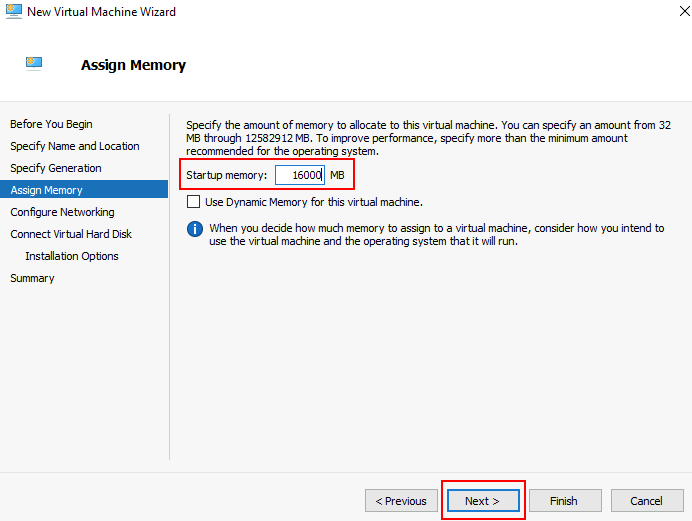
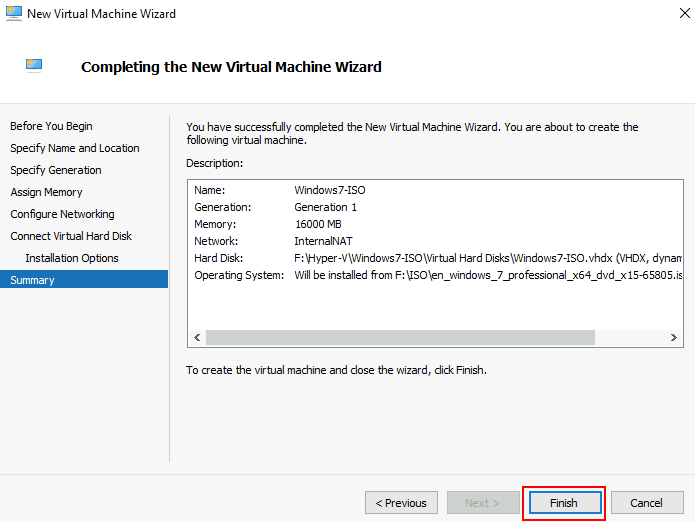
Dans cet article, nous allons déployer Azure Bastion, puis tester quelques fonctionnalités des 4 SKUs d’Azure Bastion. Bref, ne perdons pas de temps :
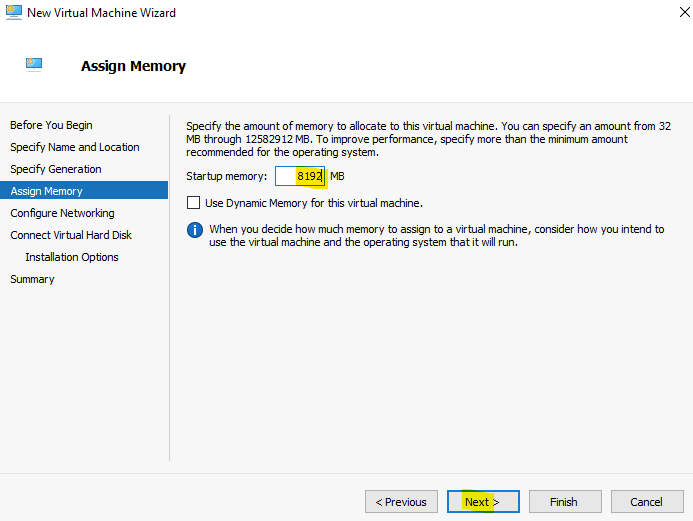
- Etape 0 – Rappel des prérequis
- Etape I – Déploiement d’Azure Bastion Développeur
- Etape II – Déploiement d’Azure Bastion Basic
- Etape III – Déploiement d’Azure Bastion Standard
- Etape IV – Déploiement d’Azure Bastion Premium
Etape 0 – Rappel des prérequis :
Pour réaliser ce nouvel exercice sur Azure Bastion, dont certaines fonctionnalités sont encore en préversion, il vous faudra disposer de :
- Un tenant Microsoft
- Une souscription Azure valide
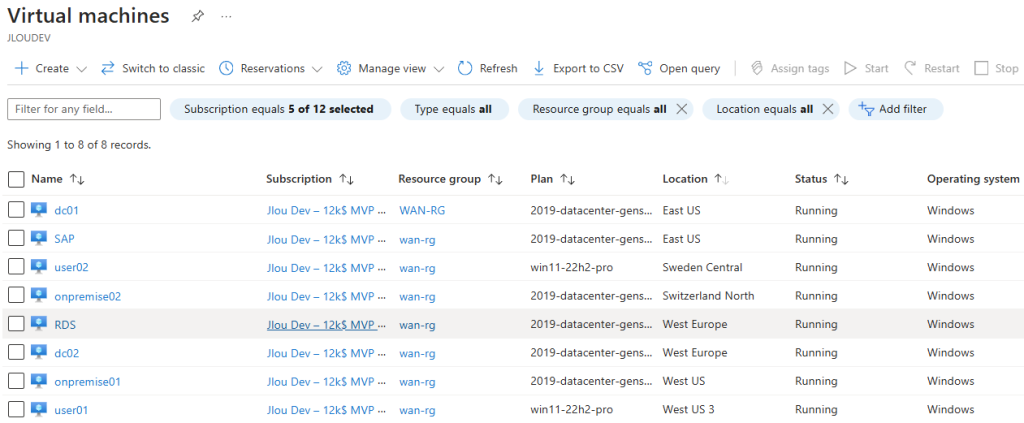
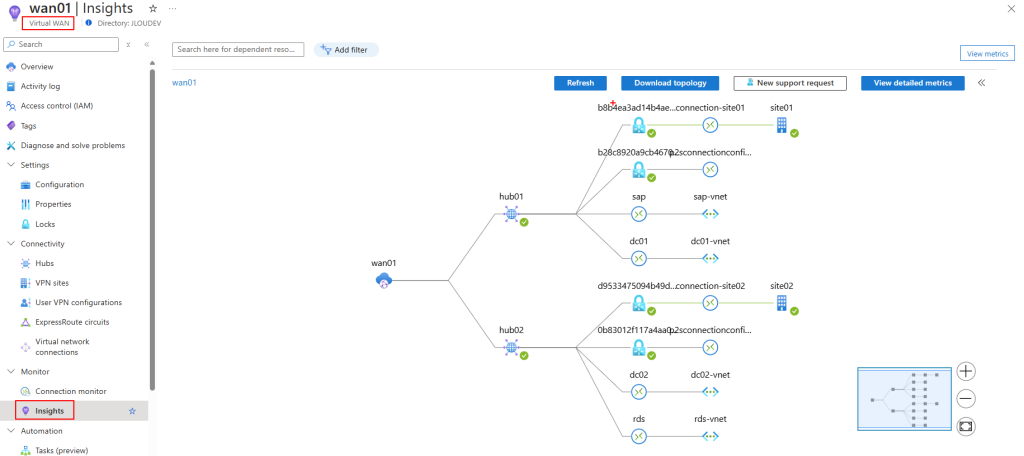
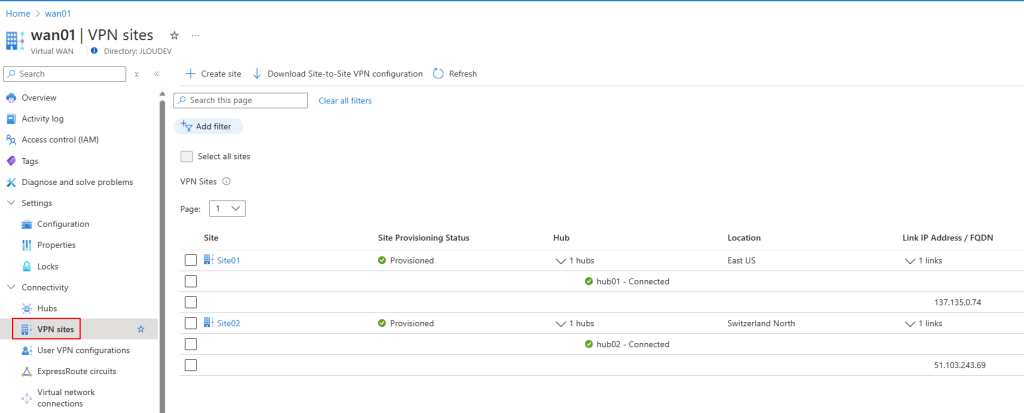
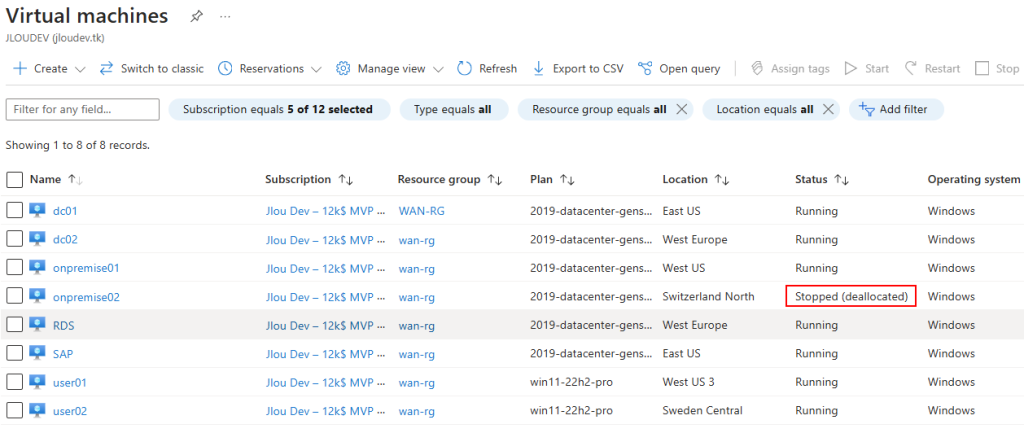
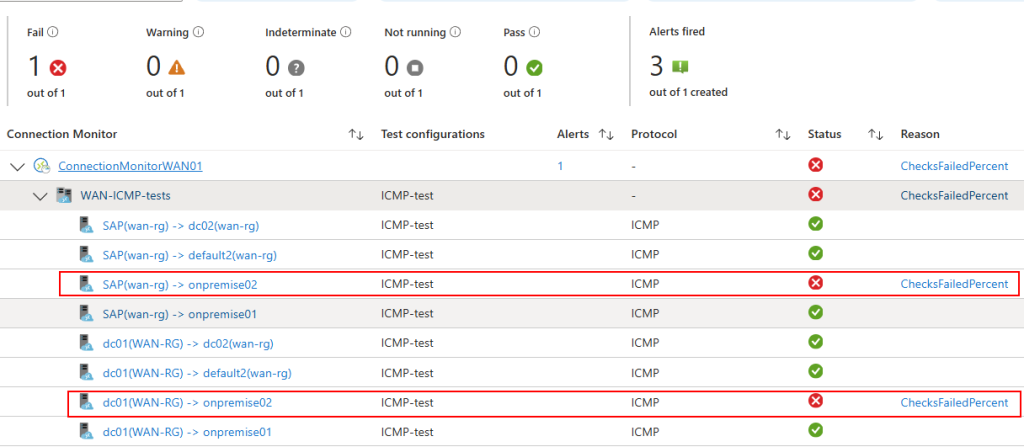
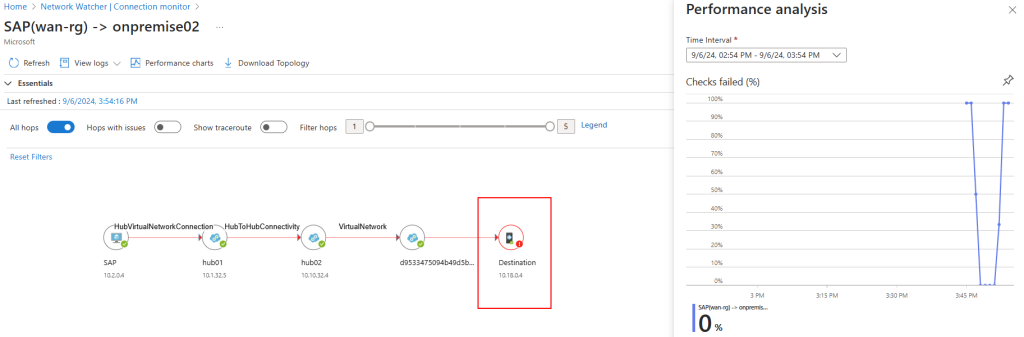
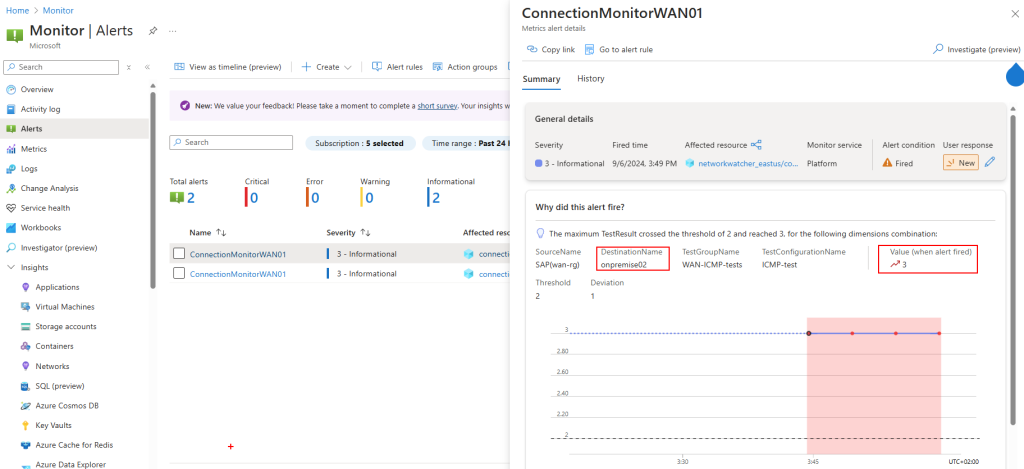
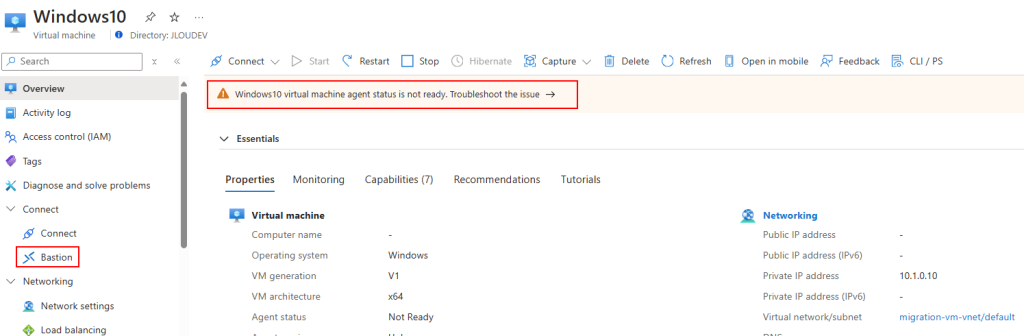
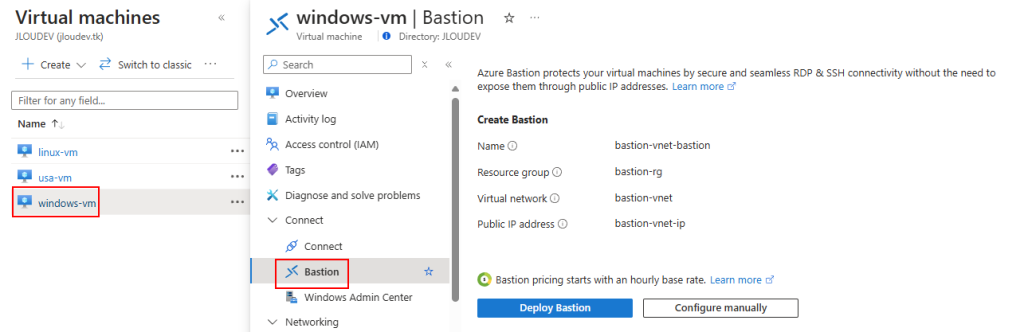
Mon environnement Azure de départ contient déjà 3 machines virtuelles :

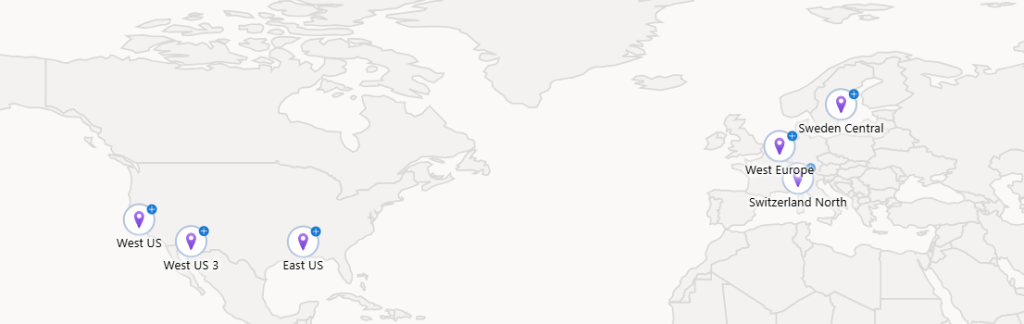
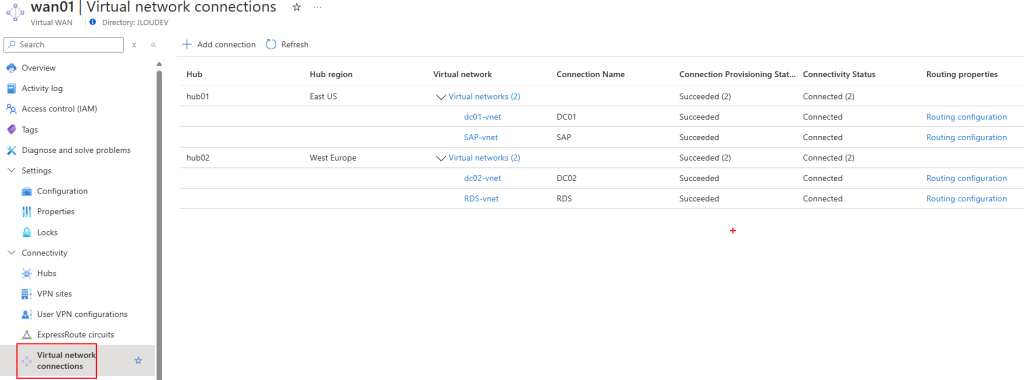
Ces 3 machines virtuelles sont réparties sur 2 réseaux virtuels déployés dans 2 régions Azure :
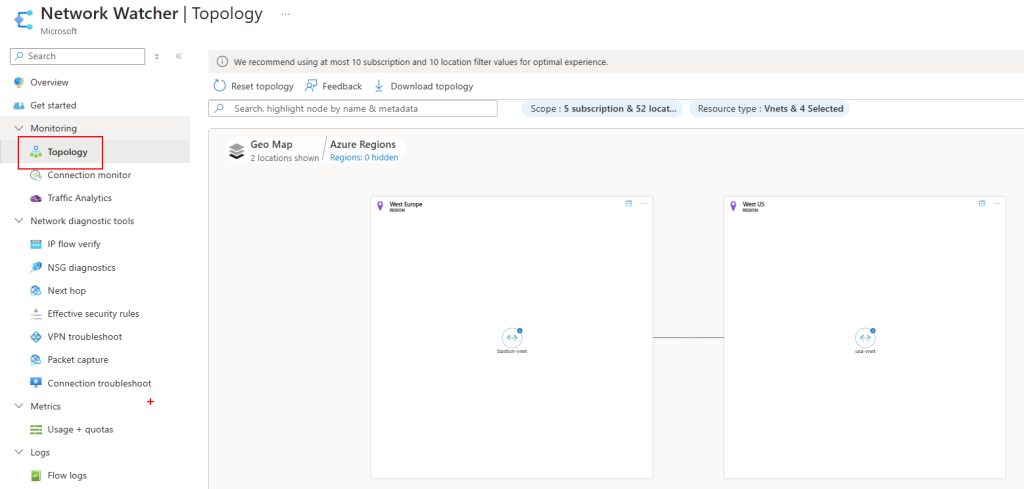
Un appairage entre ces 2 réseaux virtuels est déjà en place :
Pour information, un déploiement rapide d’Azure Bastion est possible depuis une machine virtuelle :
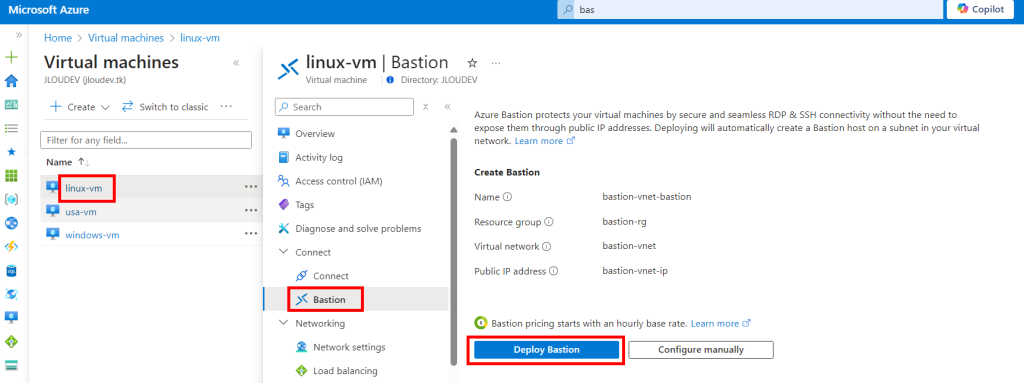
Une autre méthode de déploiement rapide d’Azure Bastion est également disponible depuis un réseau virtuel :
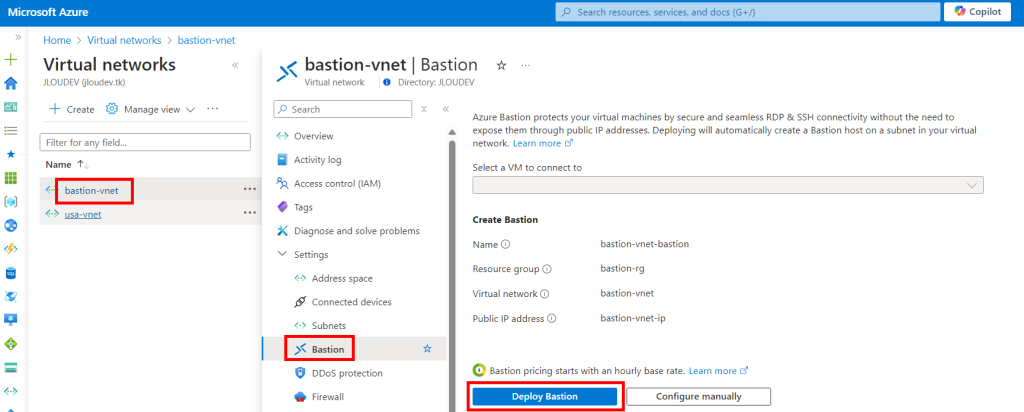
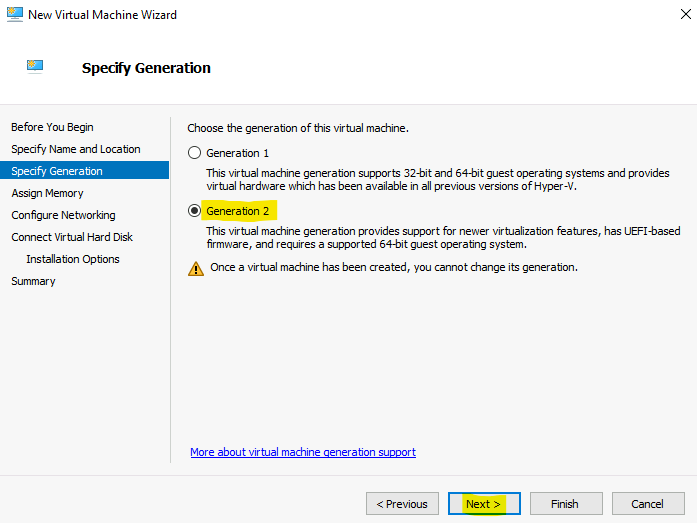
Dans notre cas, nous allons personnaliser le déploiement d’Azure Bastion afin de pouvoir sélectionner le SKU Développeur.
Etape I – Déploiement d’Azure Bastion Développeur :
Comme indiqué en introduction, ce SKU gratuit fonctionne via une ressource Azure Bastion partagée et sécurisée :
L’intérêt principal d’utiliser ce SKU d’Azure Bastion est évidemment son prix, si aucune de ses limitations n’est bloquante pour vous :
- Connexion impossible sur les réseaux virtuels appairée
- Connexions simultanées impossibles
- Authentification Kerberos impossible
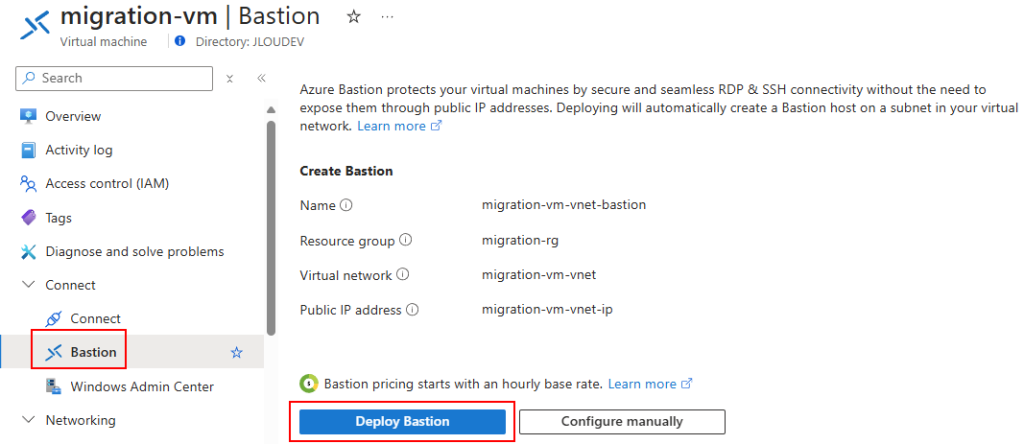
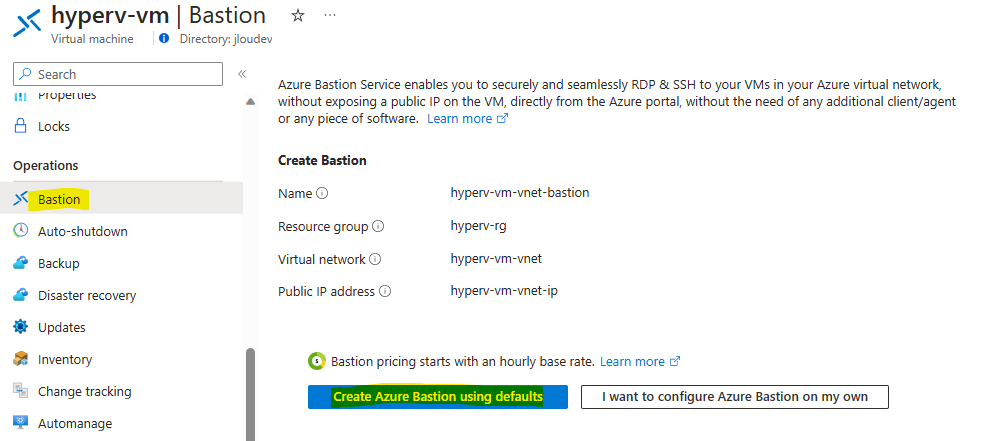
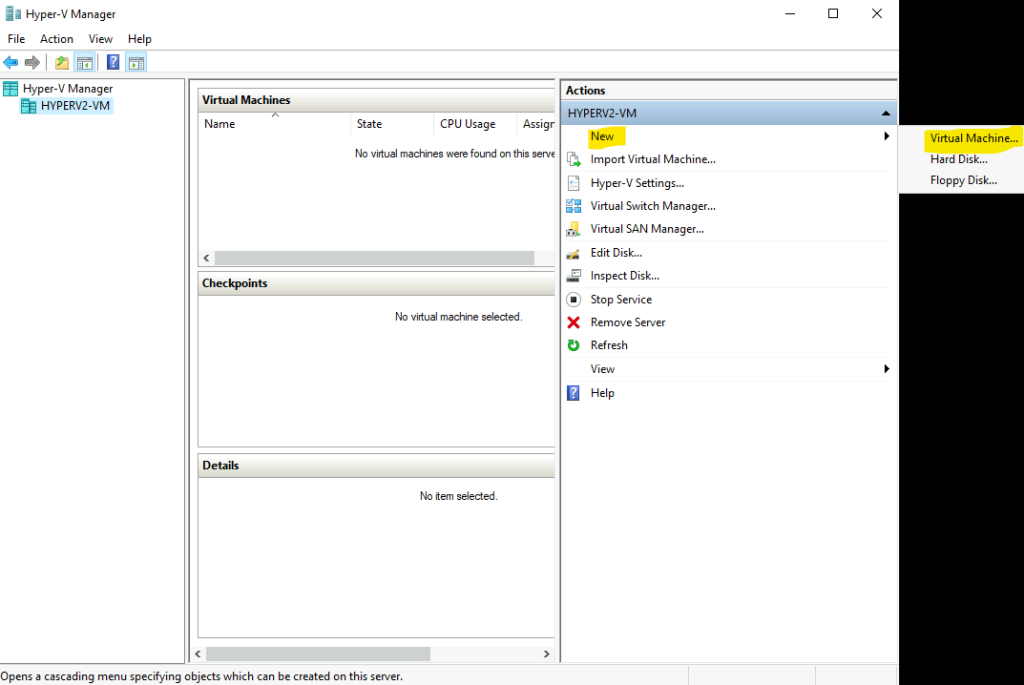
Si cela vous convient, recherchez le service Bastion dans la barre de recherche du portail Azure :
Cliquez-ici pour créer votre Azure Bastion :
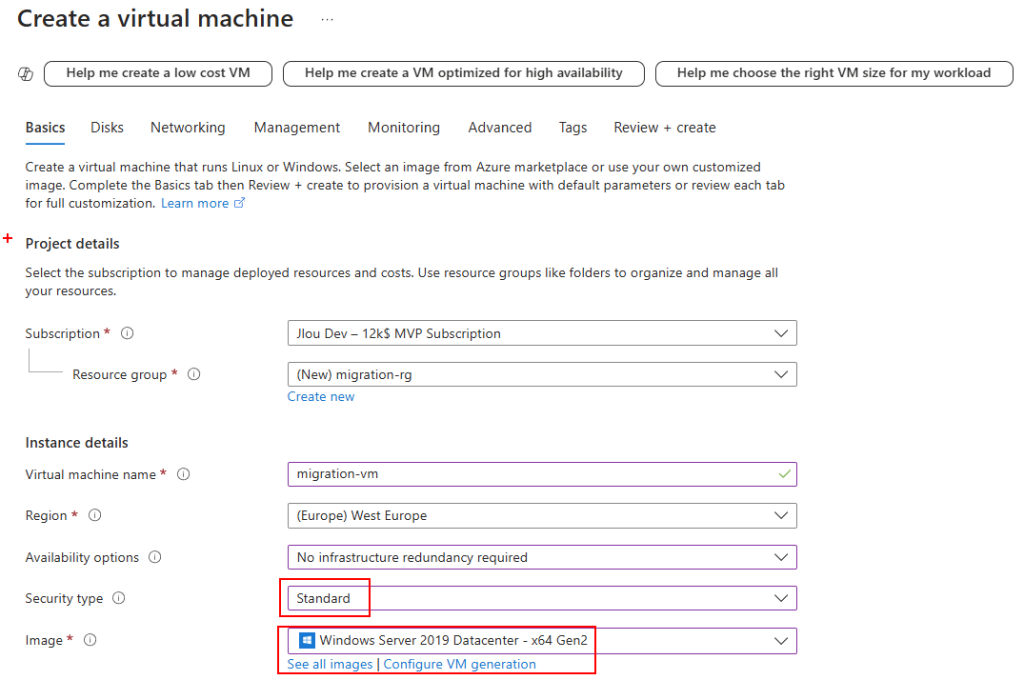
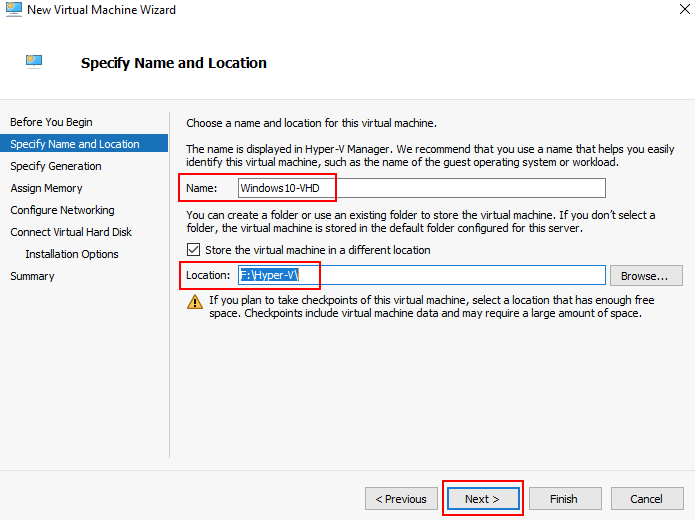
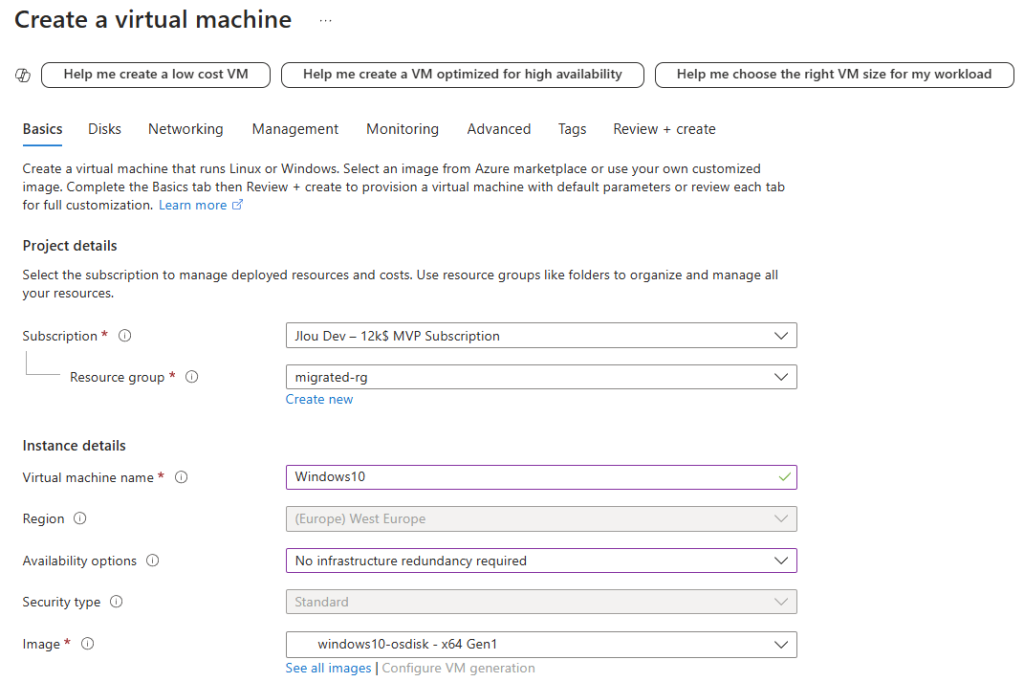
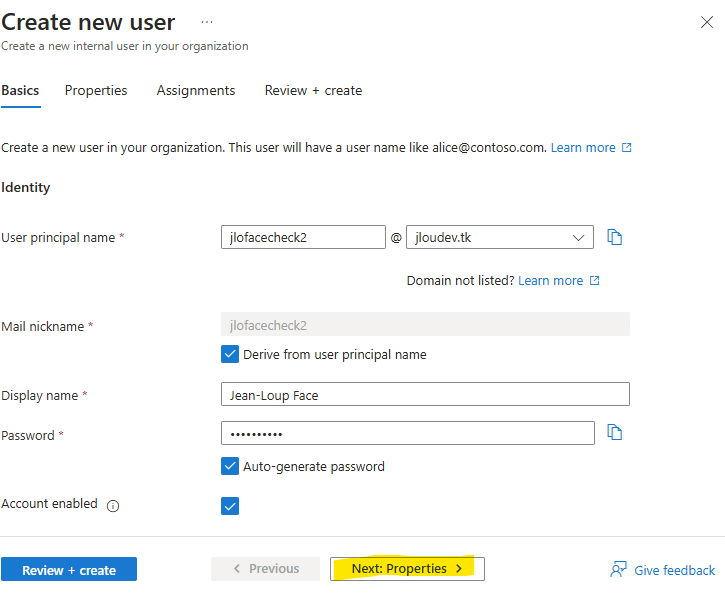
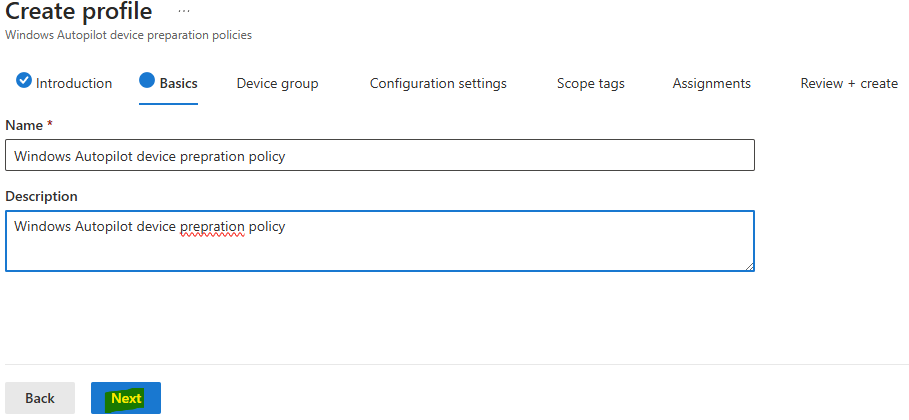
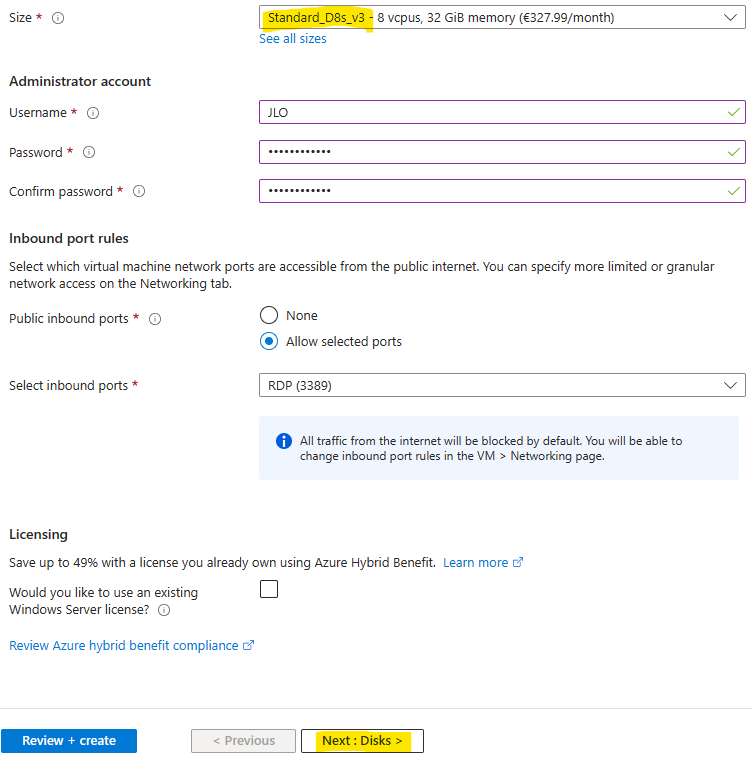
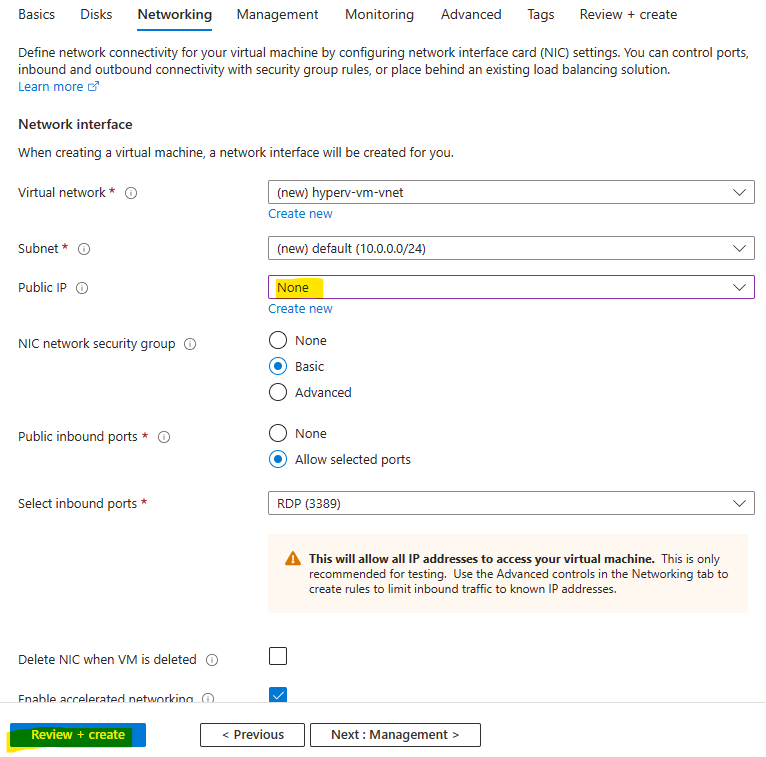
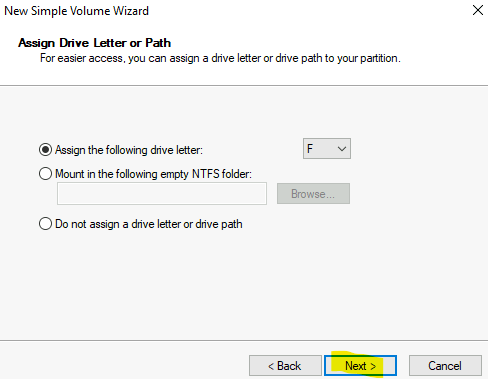
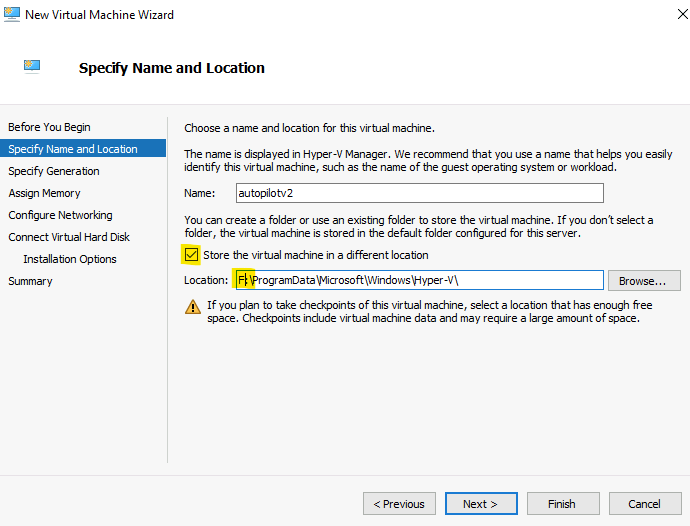
Renseignez les champs suivants :
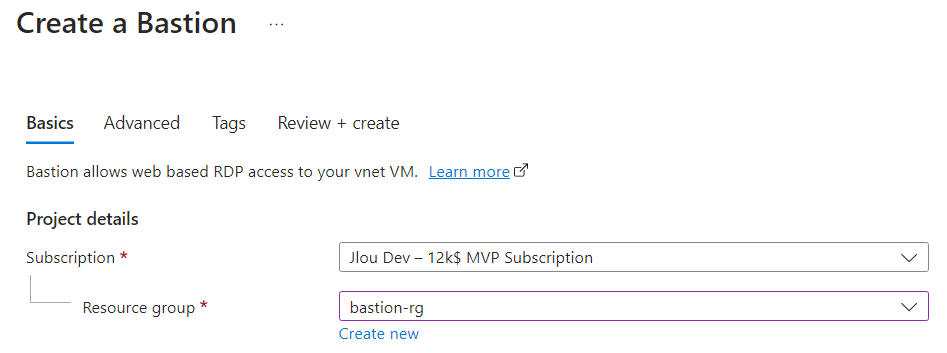
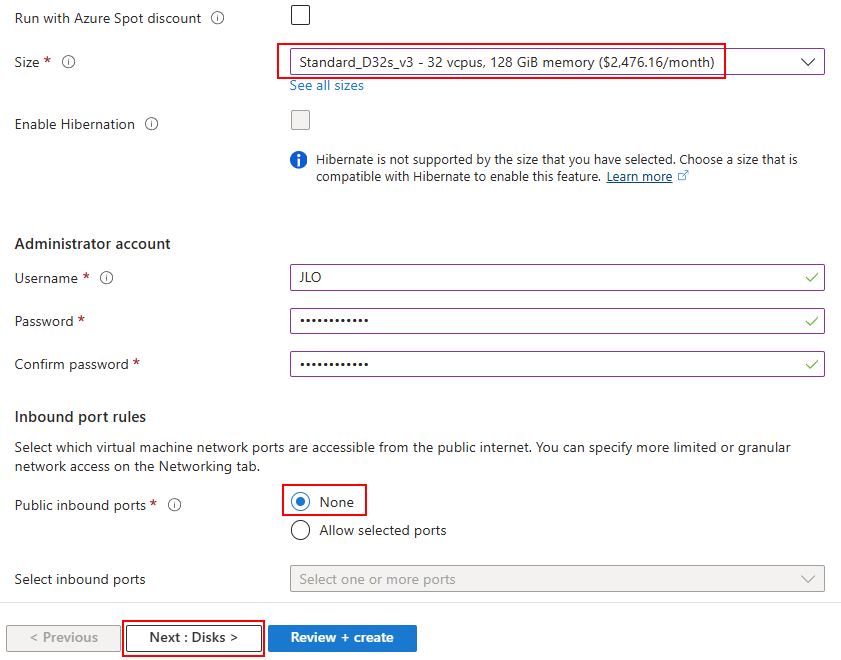
Sélectionnez le SKU Développeur :
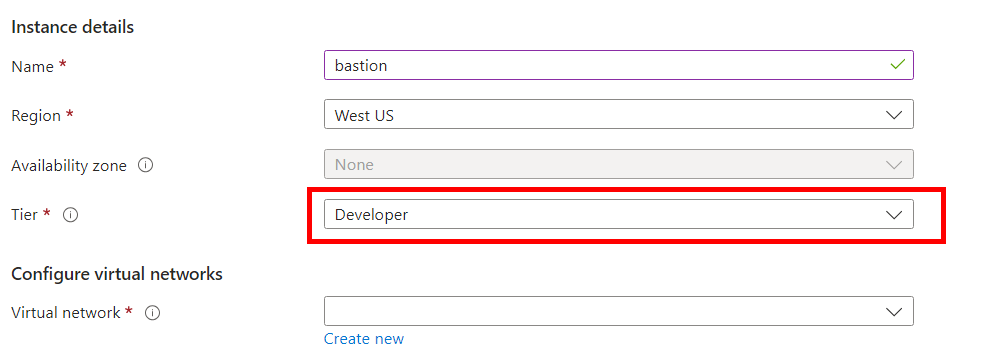
Constatez la liste réduite des régions Azure disponibles pour ce SKU :
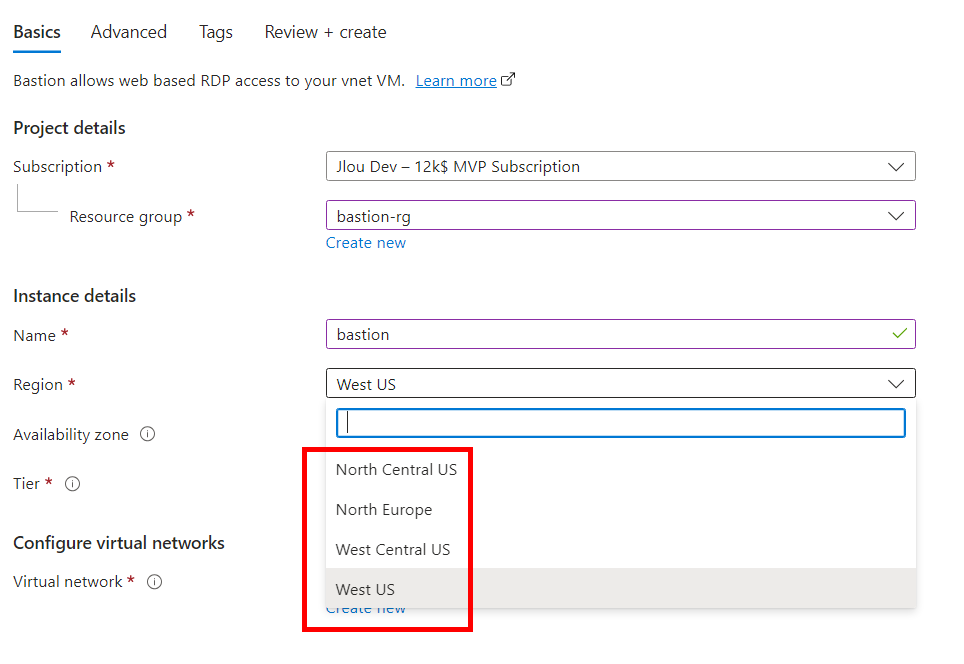
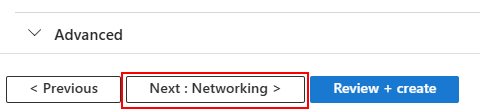
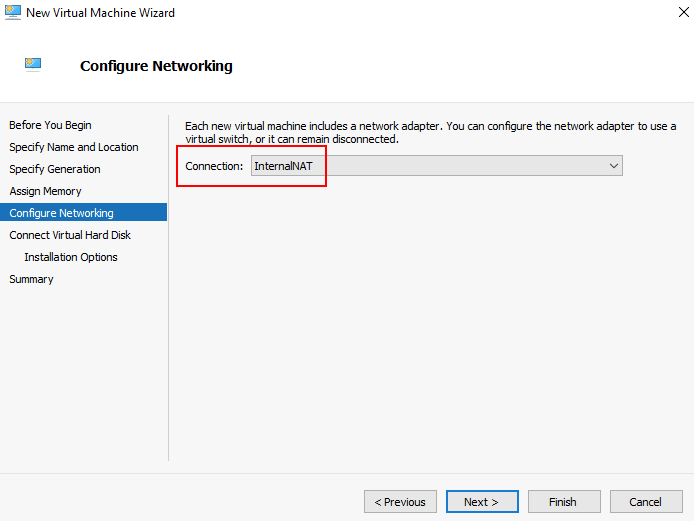
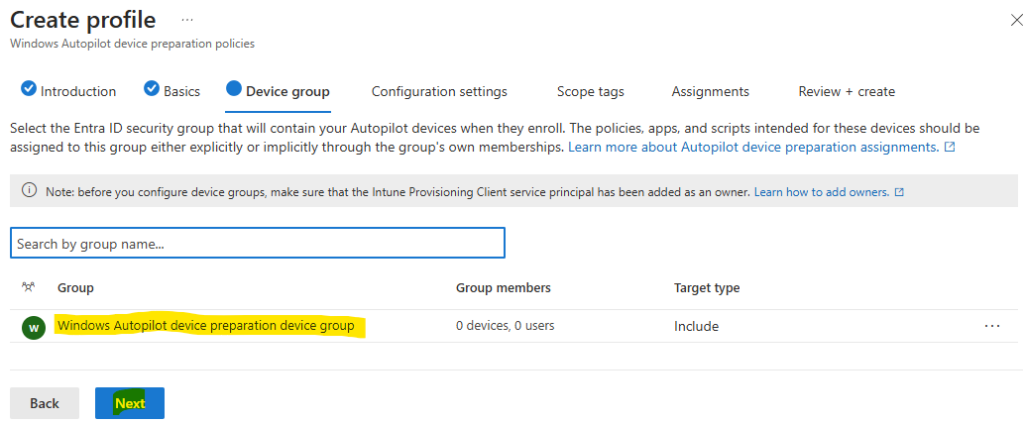
Choisissez votre réseau virtuel déjà en place, puis cliquez sur Suivant :
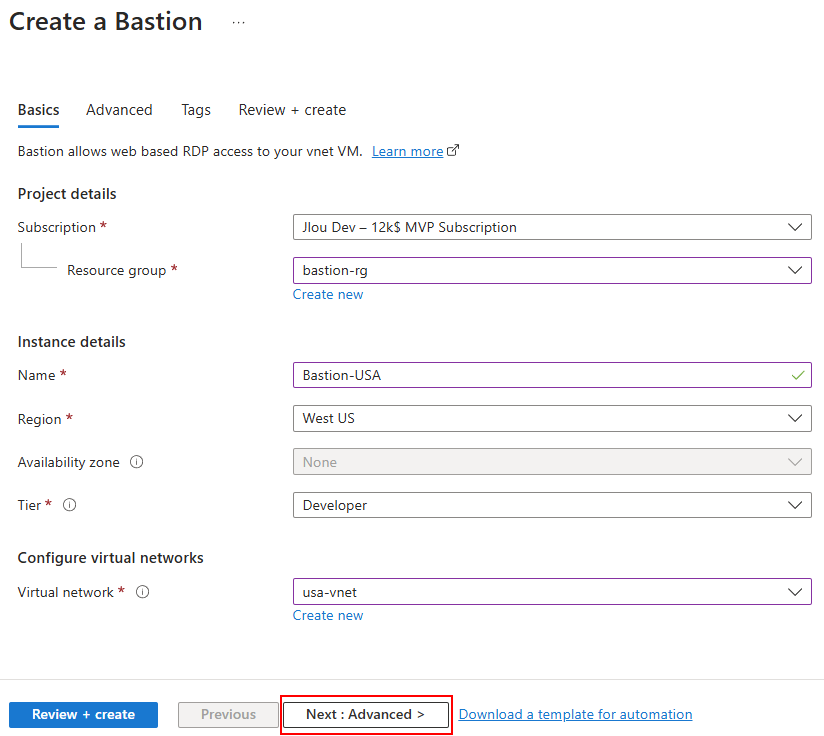
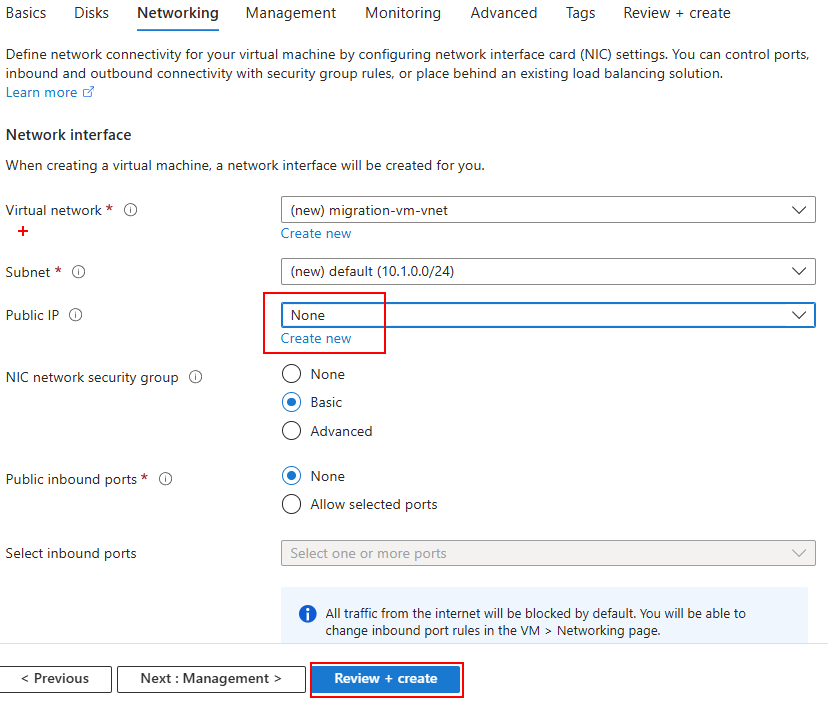
Constatez que toutes les fonctionnalités annexes sont indisponibles avec ce SKU, puis lancez la validation Azure :
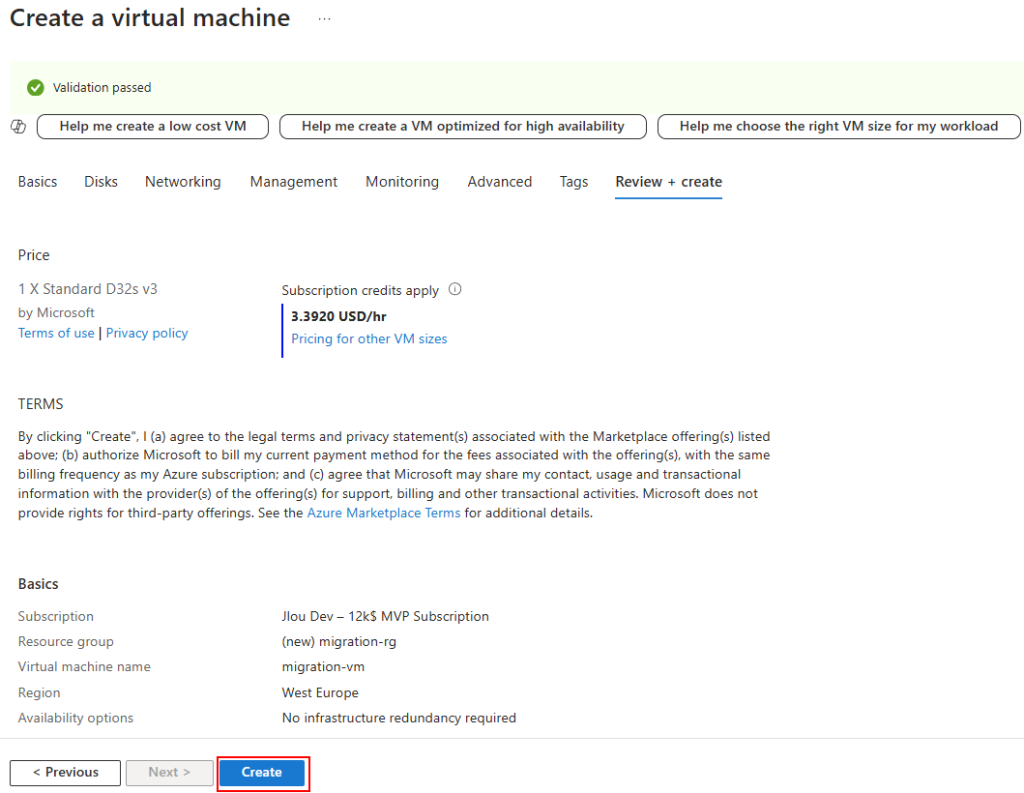
Une fois la validation réussie, lancez la création de votre Azure Bastion :
Attendez environ 1 minute pour que le service soit accessible sur votre environnement :
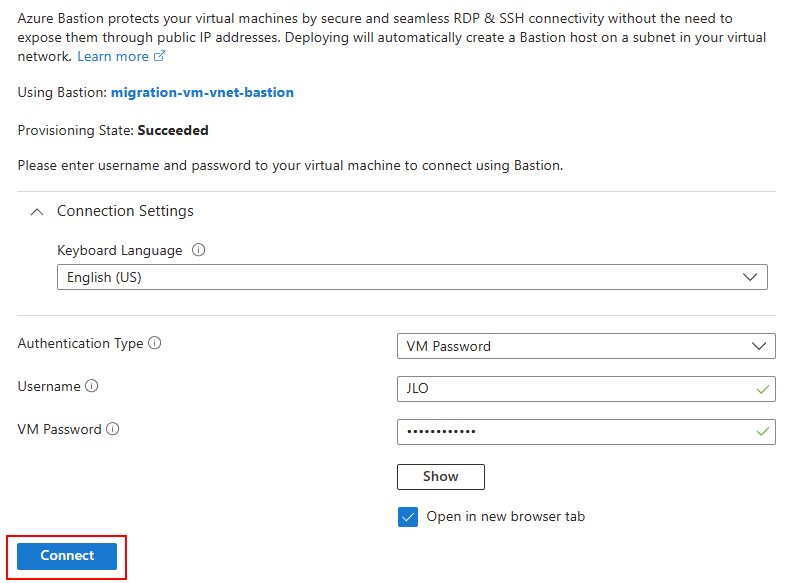
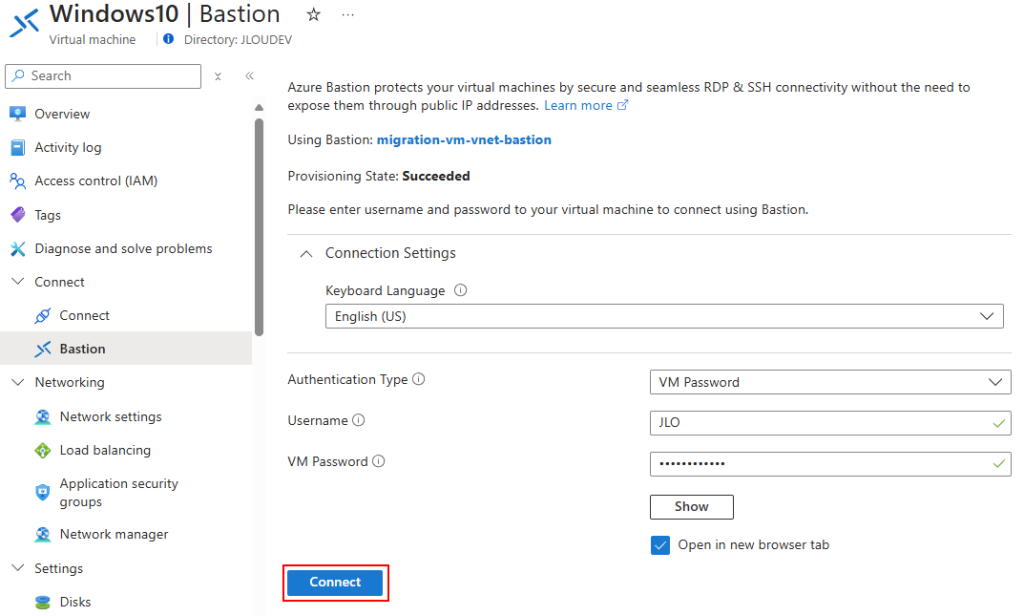
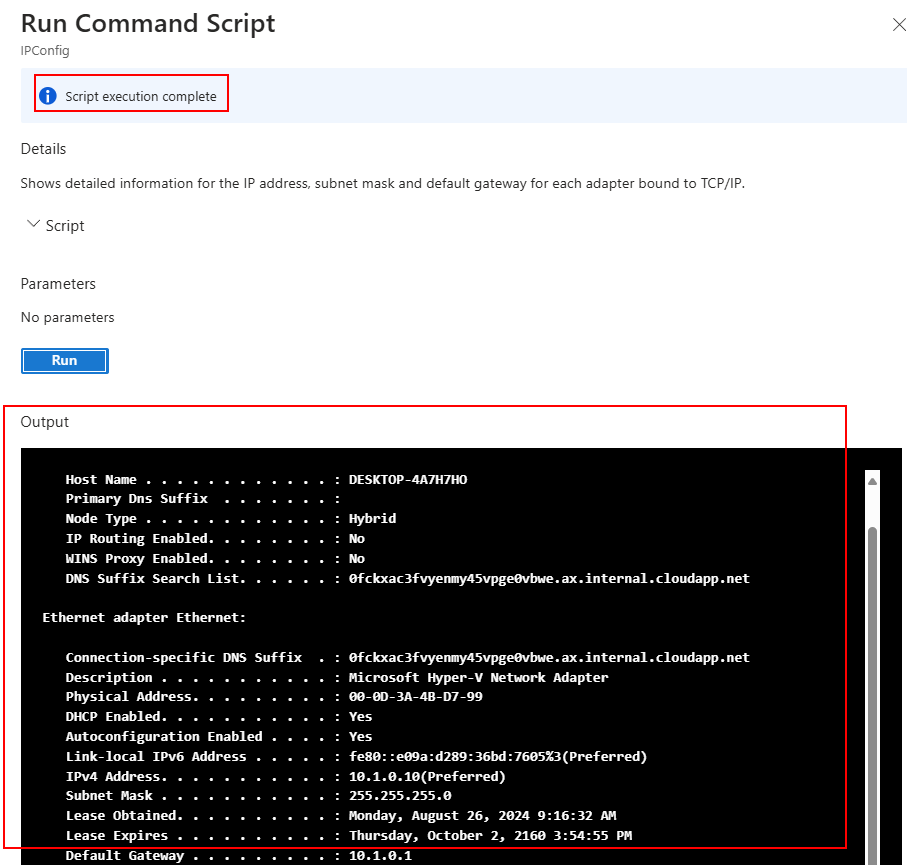
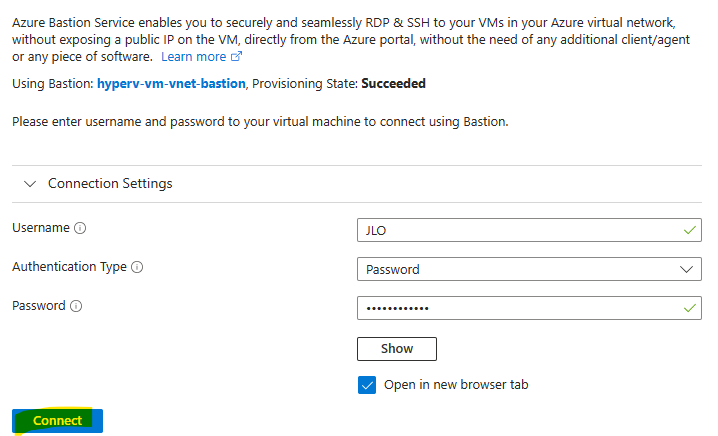
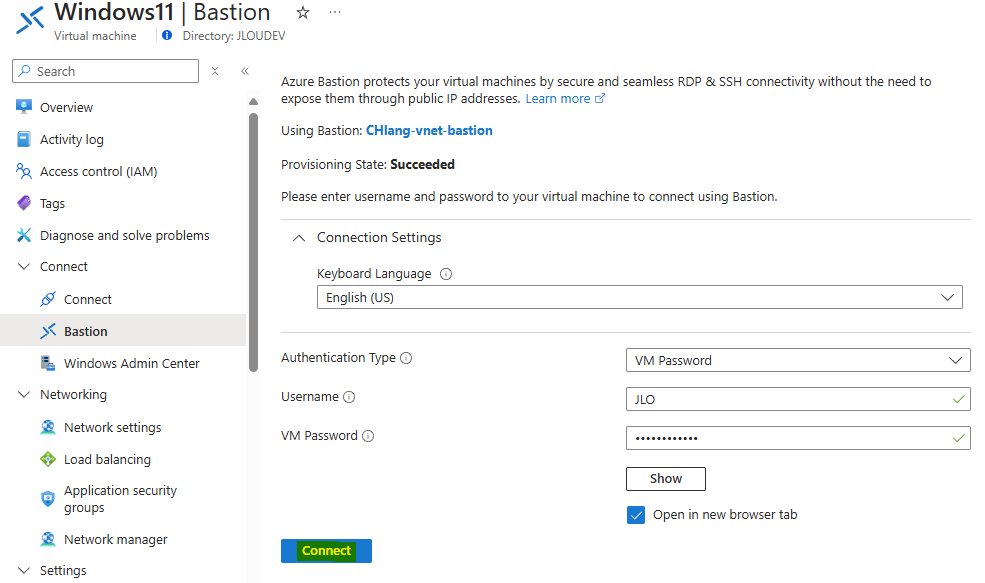
Sur une machine virtuelle présente sur le même réseau virtuel qu’Azure Bastion, connectez-vous à celle-ci :
La session de bureau à distance Windows s’ouvre bien via le protocole RDP :
Constatez l’URL spécifique de cette session Bastion pointant sur une ressource CDN :

Tentez d’utiliser votre Azure Bastion Développeur sur une autre machine virtuelle présente sur un réseau virtuel appairé au premier, sans succès :
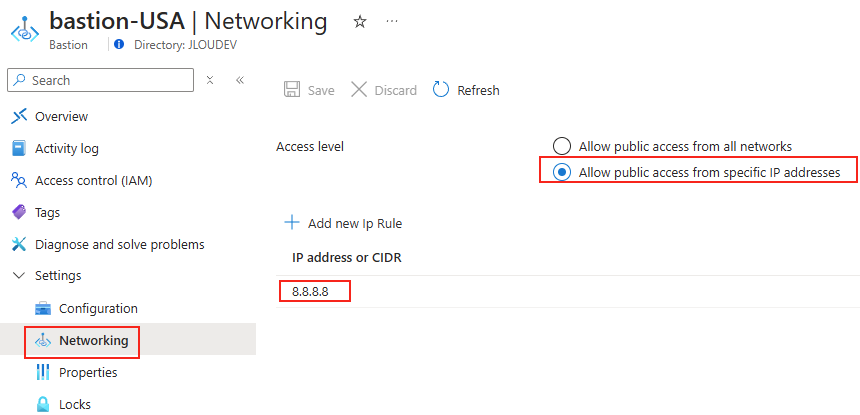
Sur ce SKU, il est malgré tout possible de restreindre les sources des sessions Bastion :
Bien que son prix soit gratuit, Azure Bastion en version Développeur limite certains besoins. Pour la suite, nous allons donc le migrer vers une gamme supérieure.
Etape II – Déploiement d’Azure Bastion Basic :
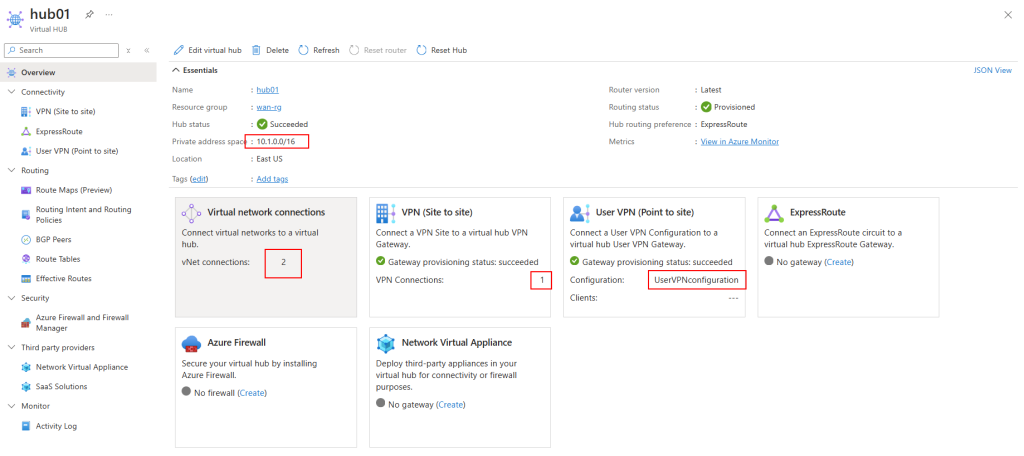
A partir de ce niveau de SKU, l’instance Azure Bastion n’est plus partagée mais dédiée à votre infrastructure. Cette intégration s’accompagne d’un sous-réseau dédié aux instances Azure Bastion :
Comparé à Bastion en version Développeur, l’intérêt d’utiliser ce SKU d’Azure Bastion repose sur les arguments suivants :
- Connexion au réseaux virtuels appairés
- Connexions simultanées
- Authentification Kerberos
- Intégration du coffre Azure Key Vault pour les clefs Linux
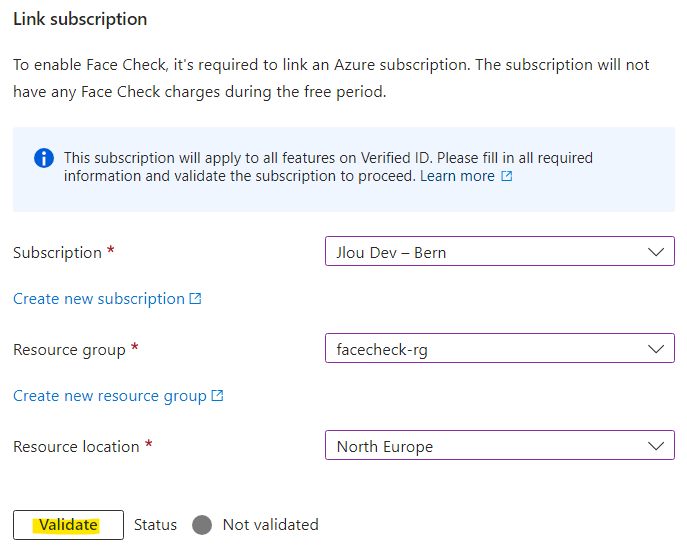
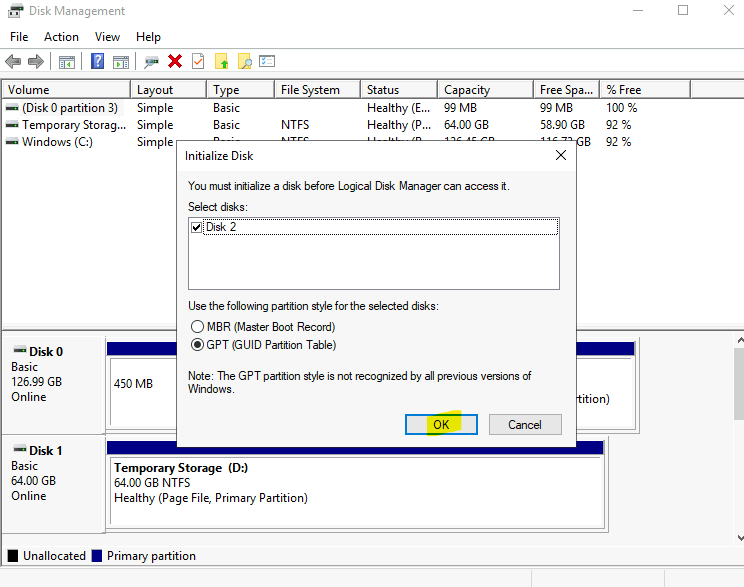
Retournez sur l’instance d’Azure Bastion Développeur déjà en place, puis mettez à jour son SKU en cliquant comme ceci :
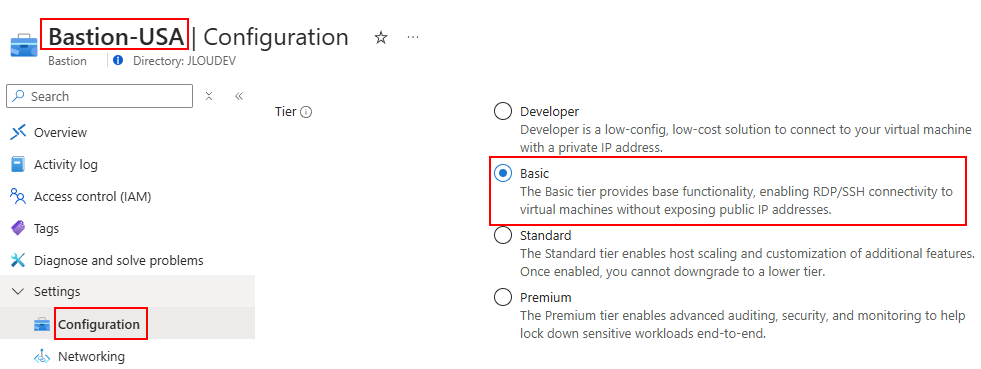
A ce moment-là, il vous est demandé de mettre en place une adresse IP publique à votre service Bastion, mais aussi de créer un sous-réseau dédié à ce dernier :
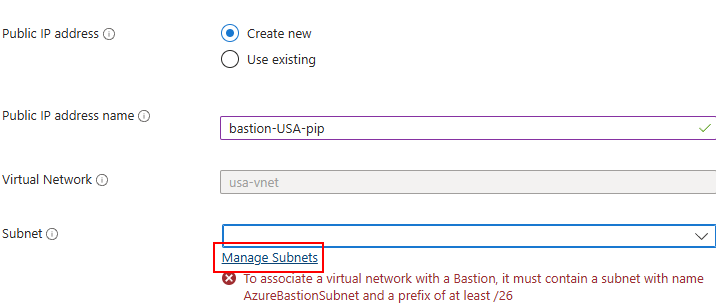
Cliquez-ici pour ajouter un nouveau sous-réseau :
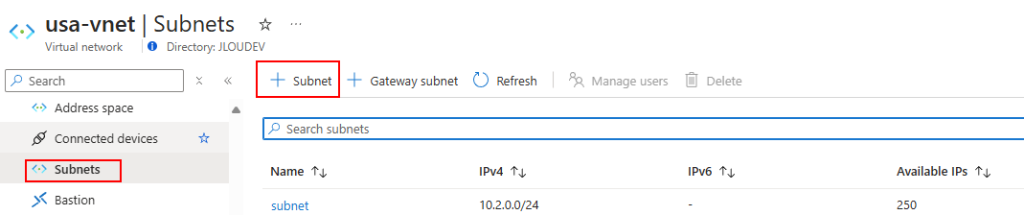
Choisissez dans la liste Azure Bastion, modifiez au besoin l’adressage puis cliquez sur Ajouter :
Une fois le sous-réseau ajouté, cliquez sur la croix en haut à droite :

Une seule option est alors dégrisée avec ce SKU, cochez-là si besoin, puis cliquez sur Appliquer :
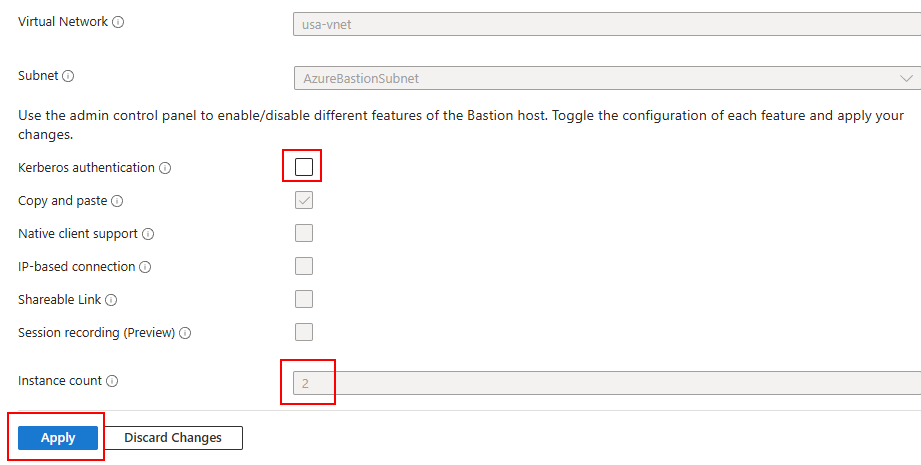
Attendez environ 5 minutes pour que le service soit mis à jour sur votre environnement :
Une fois votre Azure Bastion mis à jour, retournez sur une machine virtuelle Windows d’un réseau virtuel appairé, puis lancez une connexion via Bastion comme ceci :
Un nouvel onglet dans votre navigateur ouvre bien une session RDP de votre machine virtuelle :
Refaite le même test sur une machine virtuelle Linux :

Un nouvel onglet dans votre navigateur ouvre bien une session SSH de votre machine virtuelle :
Constatez le changement dans la nature de l’URL pointant cette fois sur un DNS dédié :

Des informations sur les sessions Bastion actuellement en cours sont également disponibles :

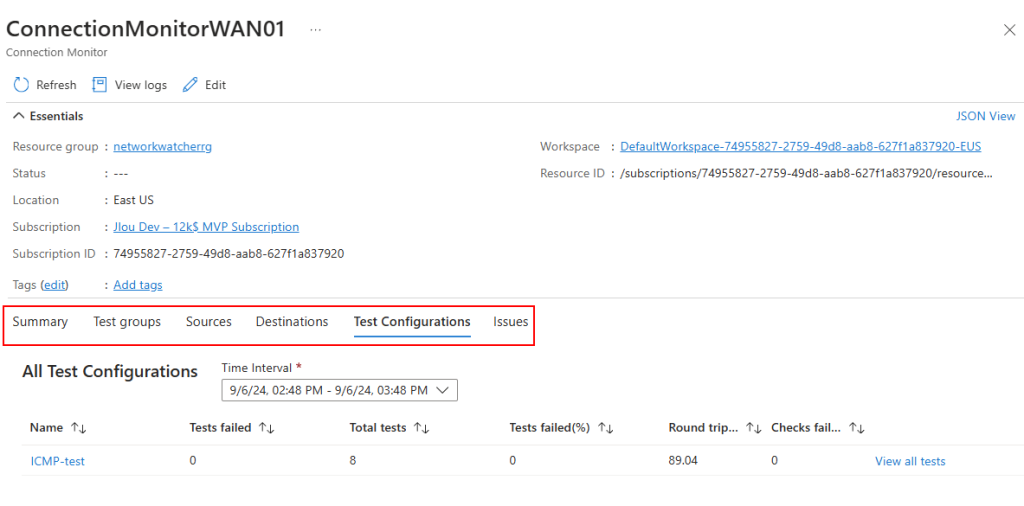
Des métriques sur les ressources de votre Azure Bastion sont également visibles :
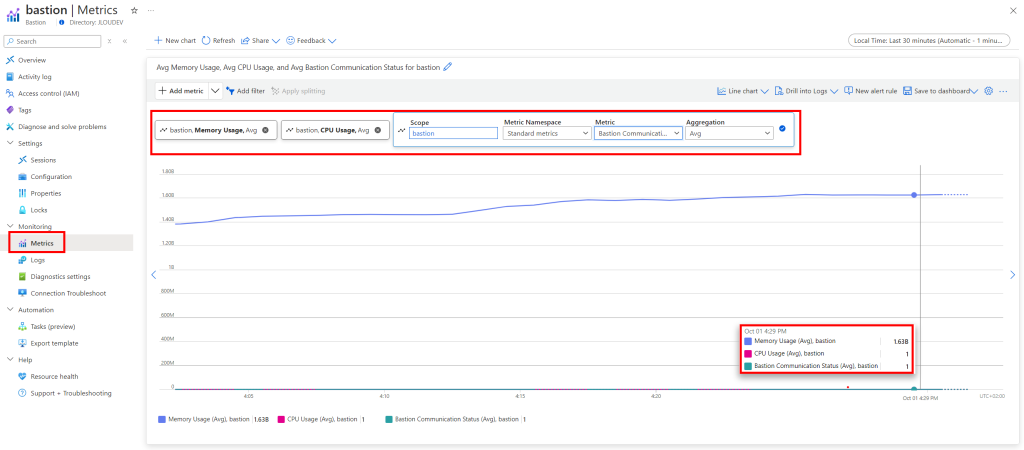
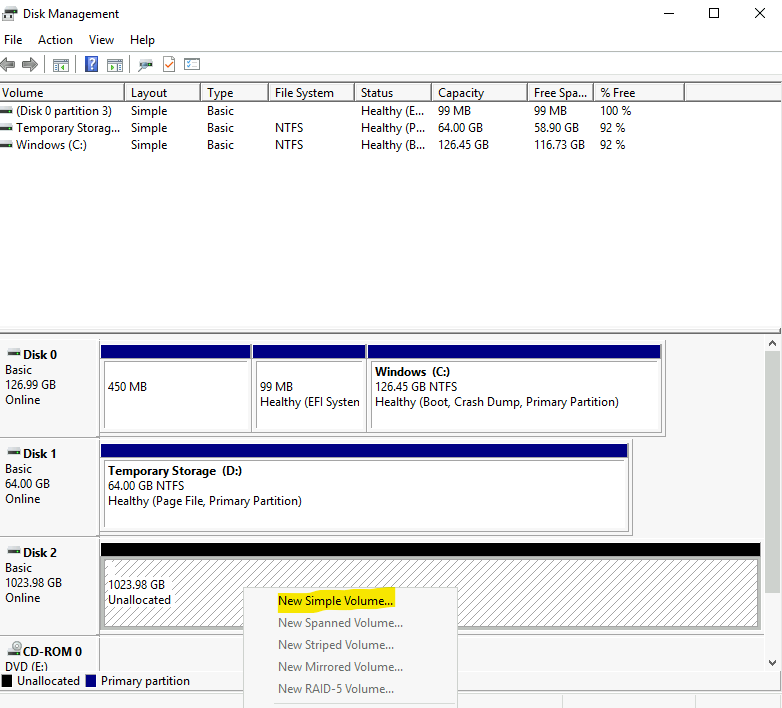
Enfin, il est également possible de constater les 2 composants Azure déployée sur ce sous-réseau dédié :
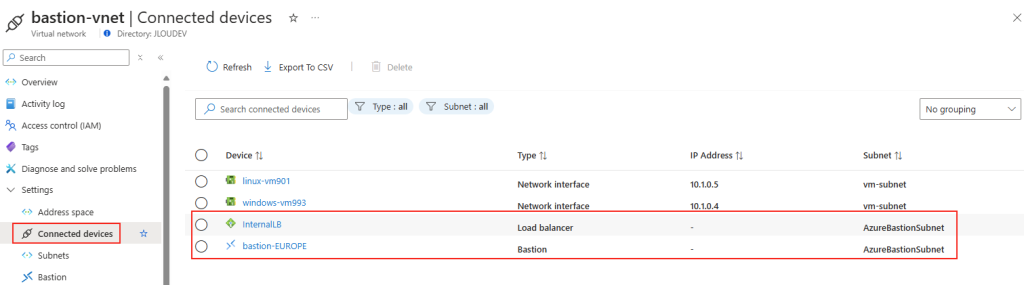
Continuons de mettre à jour notre instance Azure Bastion vers un SKU plus avancé.
Etape III – Déploiement d’Azure Bastion Standard :
Comparé à Azure Bastion de base, l’intérêt ce SKU d’Azure Bastion repose sur les arguments suivants :
- Connexions via adresse IP
- Connexions Linux en RDP
- Connexions Windows en SSH
- Personnalisation du port d’entrée possible
- Augmentation du nombre d’instances
- Génération de lien partageable
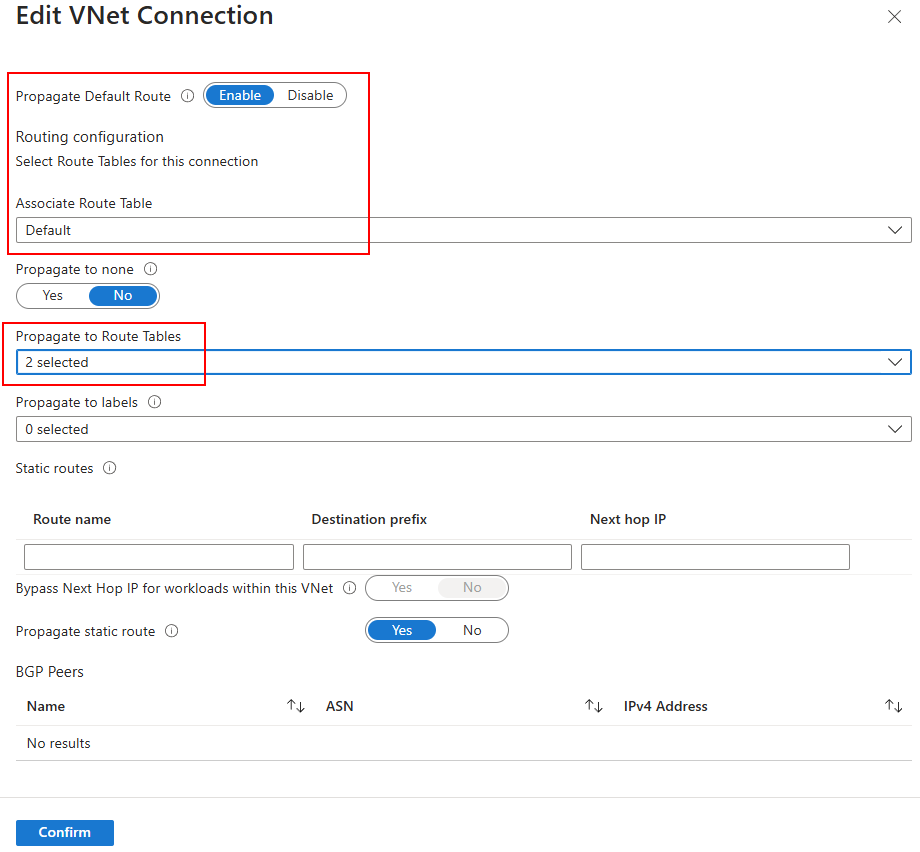
De nouvelles options sont dégrisées avec ce SKU, cochez-les si besoin, puis cliquez sur Appliquer :
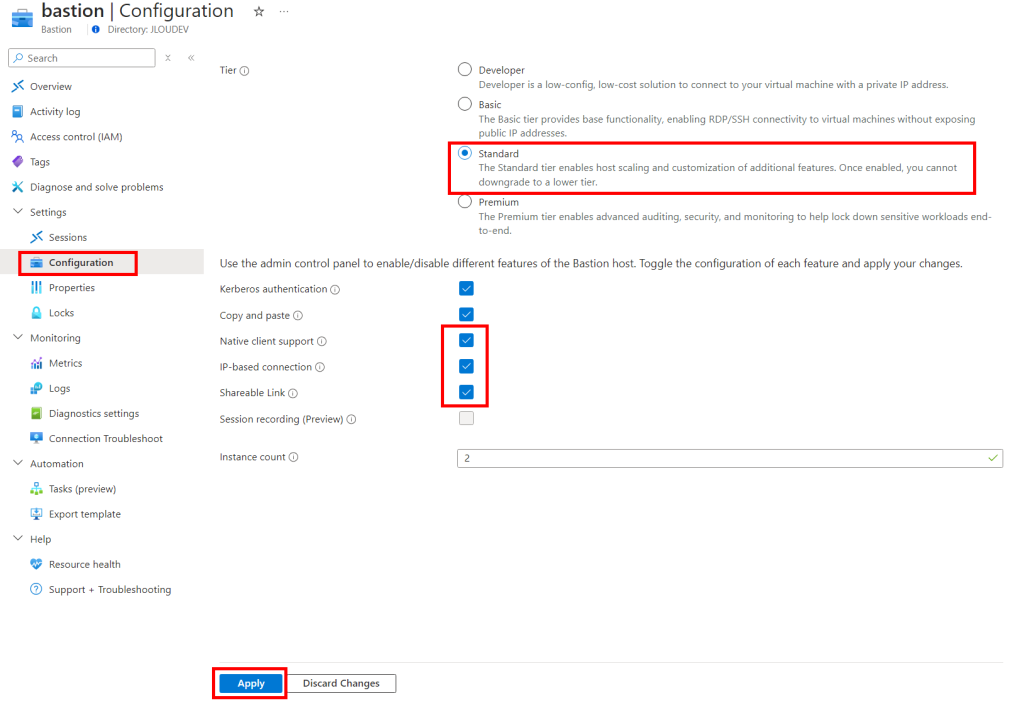
Attendez environ 5 minutes pour que le service soit mis à jour sur votre environnement :
Une fois votre Azure Bastion mis à jour, un nouveau menu dédié aux liens partagés fait son apparition dans les paramètres votre Azure Bastion.
Cliquez-ici pour créer votre premier lien partagé :
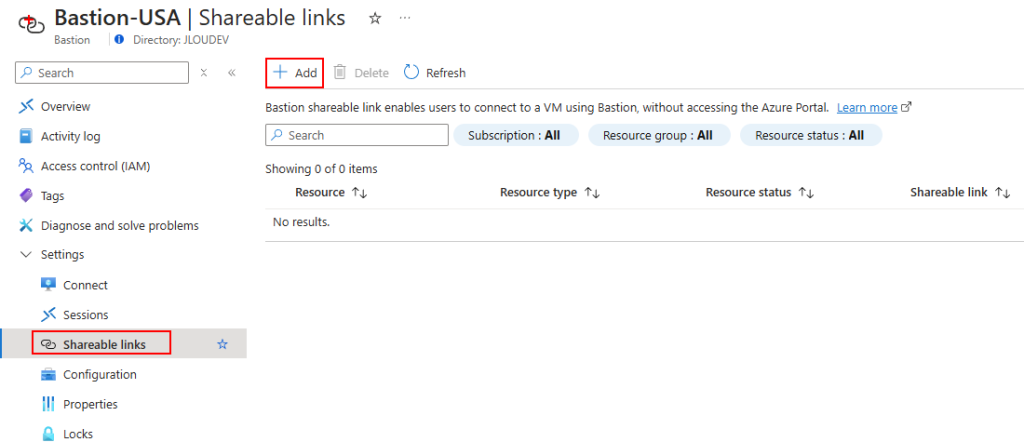
Choisissez la machine virtuelle cible, puis cliquer sur Appliquer :
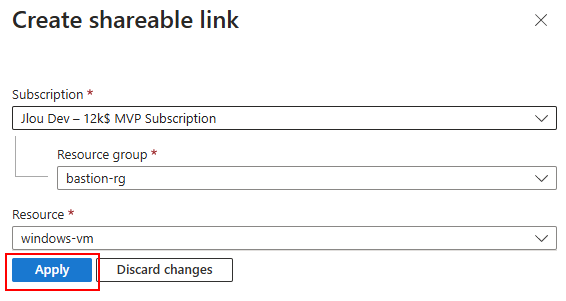
Le nouveau lien partagé s’ajoute aux liens déjà générés, copiez votre lien dans le presse-papier :

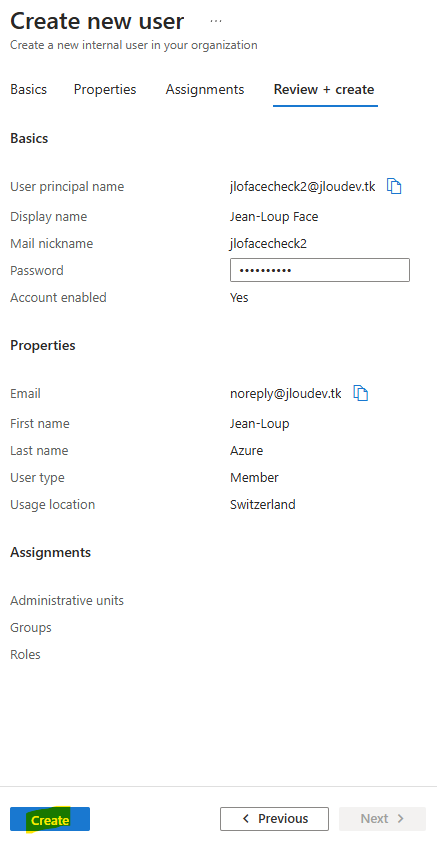
Ouvrez un navigateur privé, puis collez votre lien partageable dans la barre d’adresse, renseignez les identifiants de l’administrateur, puis cliquez-ici pour ouvrir la session :
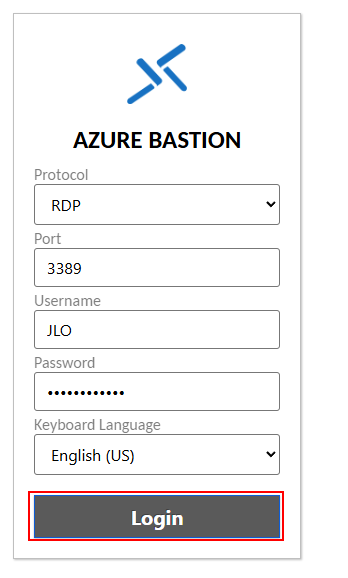
Attendez quelques secondes, puis constatez l’ouverture du bureau à distance Windows :
Après avoir fermé la session Windows ouverte grâce au lien partagé, pensez à supprimer le lien généré :
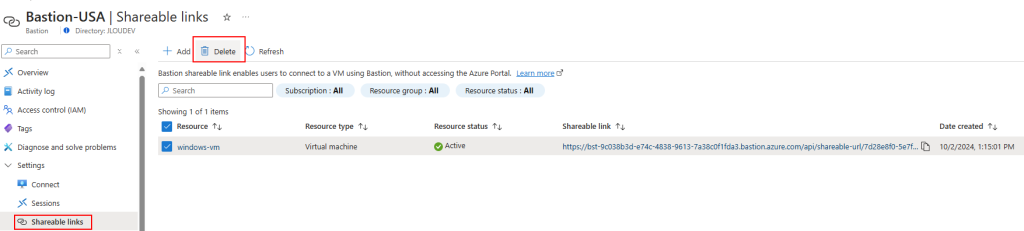
Retournez sur la configuration d’Azure Bastion afin de faire varier le nombre d’instances, puis cliquez sur Appliquer :

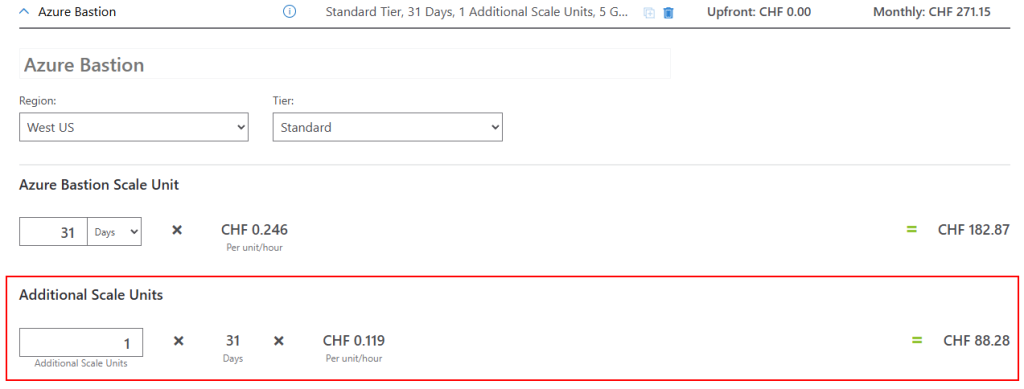
Chaque instance peut prendre en charge 20 connexions RDP simultanées et 40 connexions SSH simultanées pour les charges de travail moyenne.
Si une instance supplémentaire est déployée, un coût additionnel est ajouté :
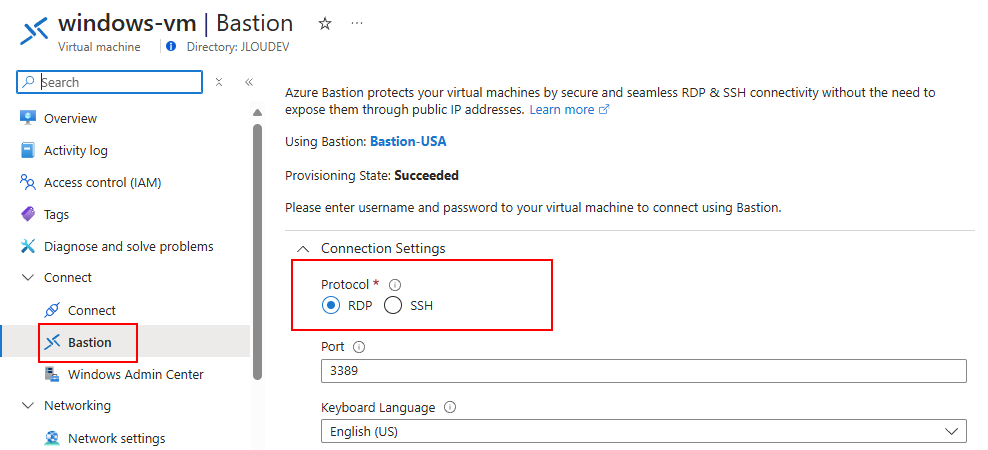
Azure Bastion propose de choisir le protocole et le port d’entrée pour les machines virtuelles :
Continuons de mettre à jour notre instance Azure Bastion vers un SKU plus avancé.
Etape IV – Déploiement d’Azure Bastion Premium :
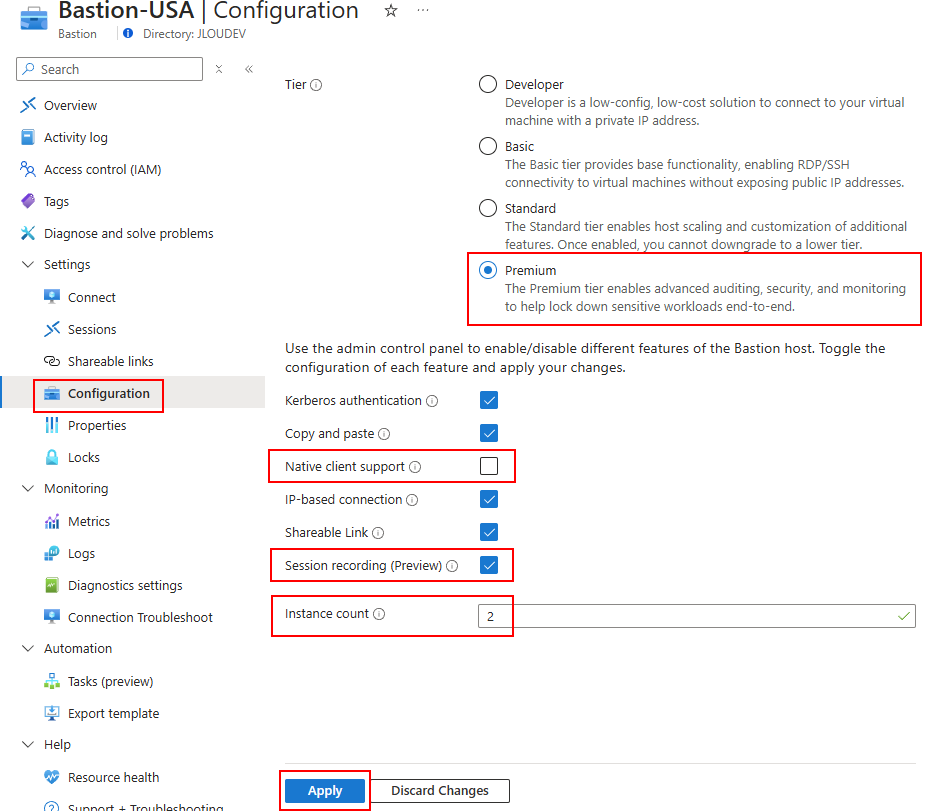
Comparé à Azure Bastion Standard, l’intérêt d’utiliser ce nouveau SKU d’Azure Bastion repose sur les arguments suivants :
- Enregistrement de session
- Déploiement privé uniquement
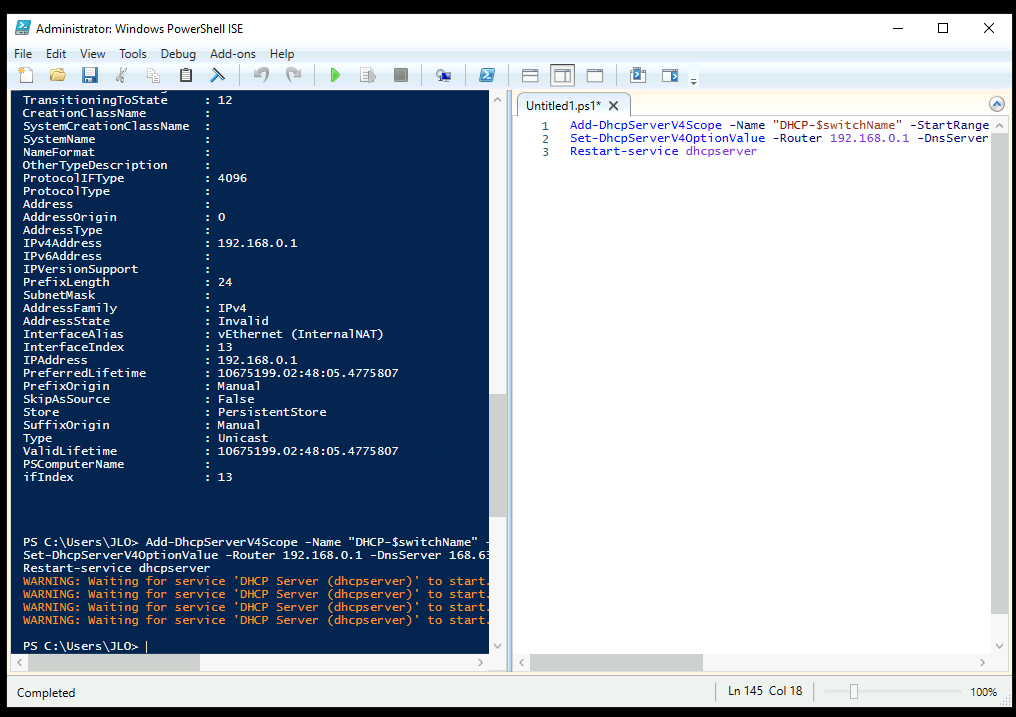
Toutes les options sont alors dégrisées avec ce SKU, cochez-les si besoin, puis cliquez sur Appliquer :
Attendez environ 5 minutes pour que le service Bastion soit mis à jour sur votre environnement.
Enregistrement de session
Une fois mis à jour, copiez le nom DNS privé de votre service :

Afin de tester l’enregistrement de session d’Azure Bastion, il est nécessaire de créer un compte de stockage :
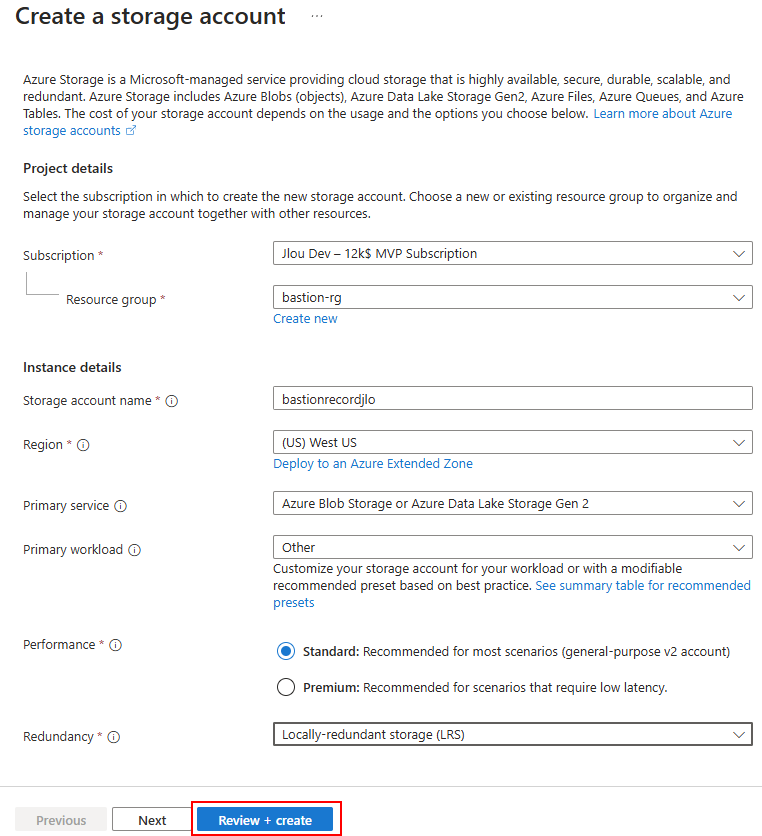
Une fois le compte de stockage créé, renseignez l’origine en reprenant le protocole https:// suivi du nom DNS privé de votre Azure Bastion.
Cela donne dans mon cas :
https://bst-9c038b3d-e74c-4838-9613-7a38c0f1fda3.bastion.azure.com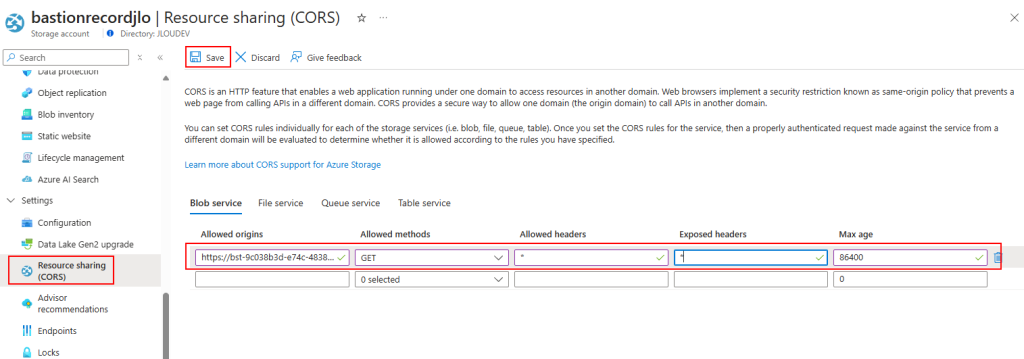
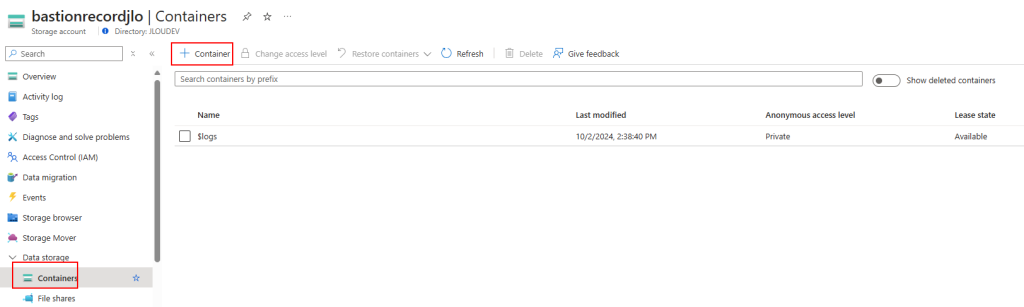
Cliquez ici pour créer un conteneur objet blob dédié :
Dans ce nouveau conteneur, créez une clef SAS avec les propriétés suivantes :
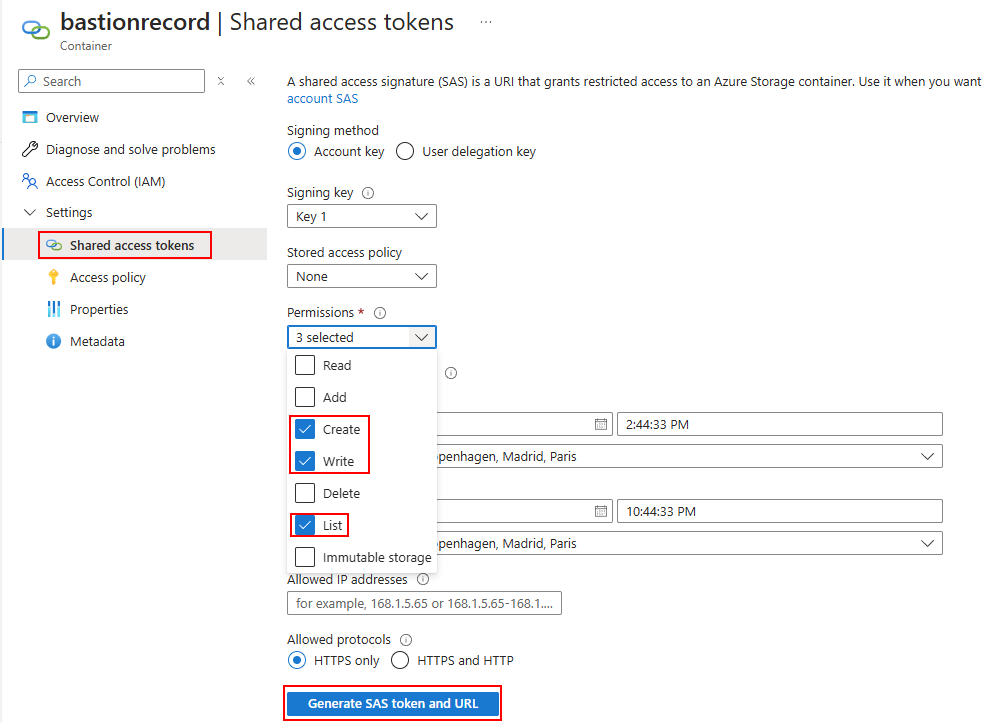
Copiez l’URL de votre nouvelle clef SAS :
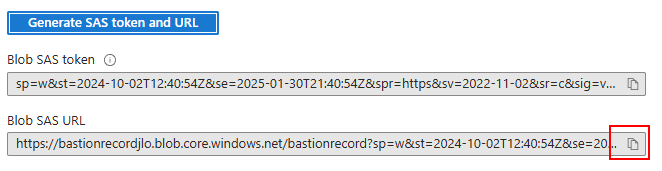
Retournez sur votre service Azure Bastion afin de rajouter ce stockage :
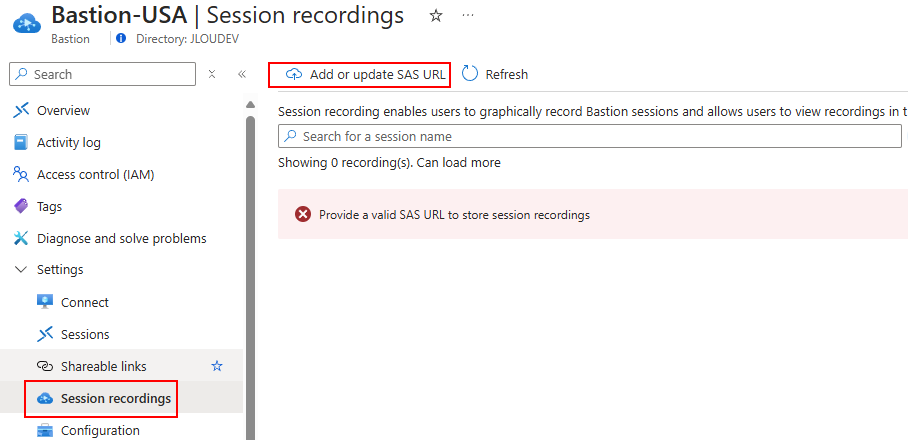
Collez votre clef SAS, puis cliquez sur le bouton suivant :
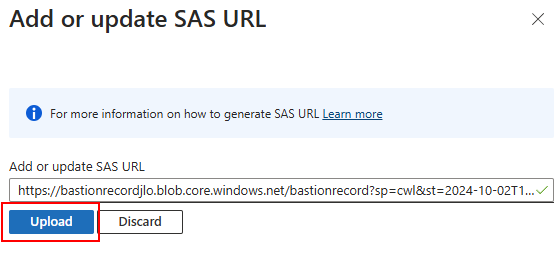
Vérifiez l’absence de message d’erreur ou d’avertissement :
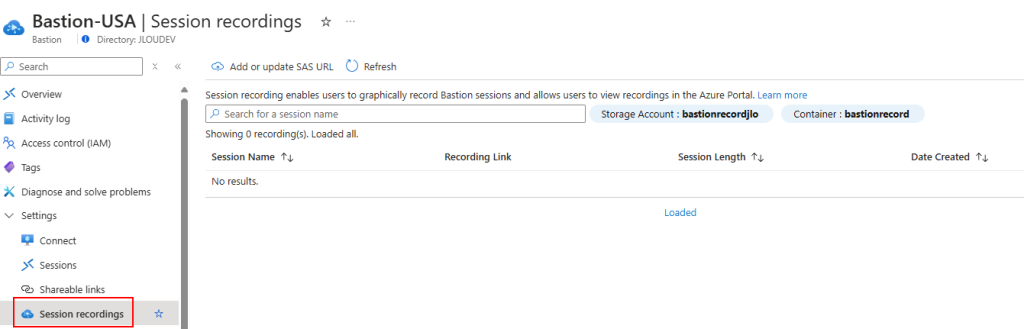
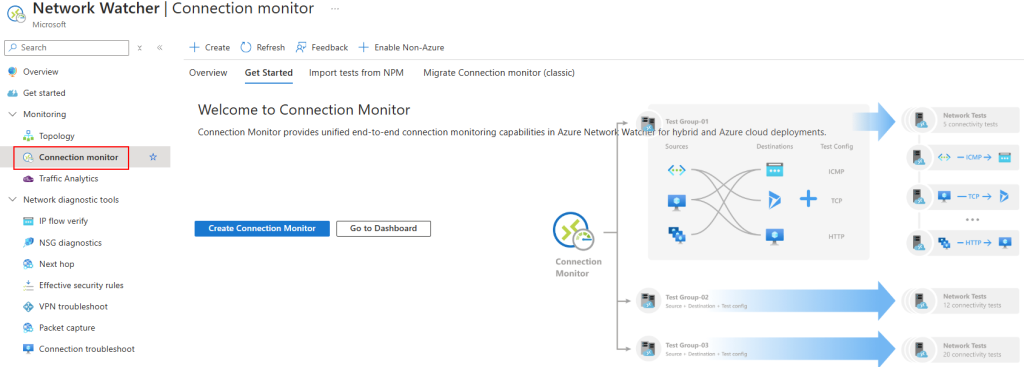
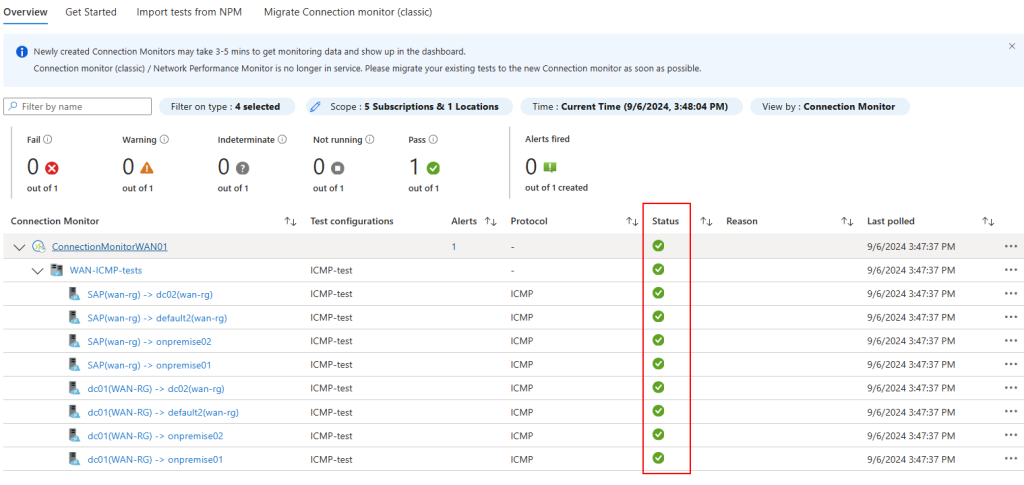
Testez l’enregistrement d’une session SSH en ouvrant une nouvelle connexion via Azure Bastion :

Après avoir terminé des manipulations dans votre session SSH, constatez l’apparition d’un blob sur le conteneur créé :
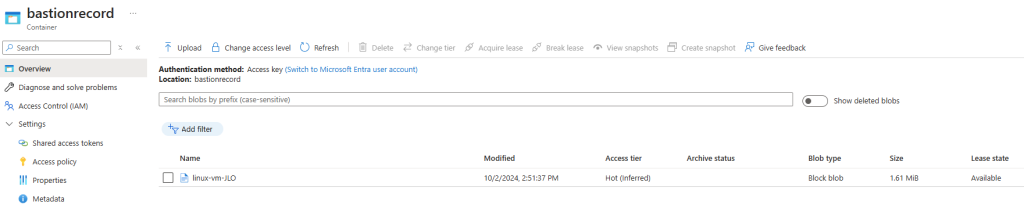
Constatez également l’apparition d’un enregistrement directement visualisable en cliquant ici :
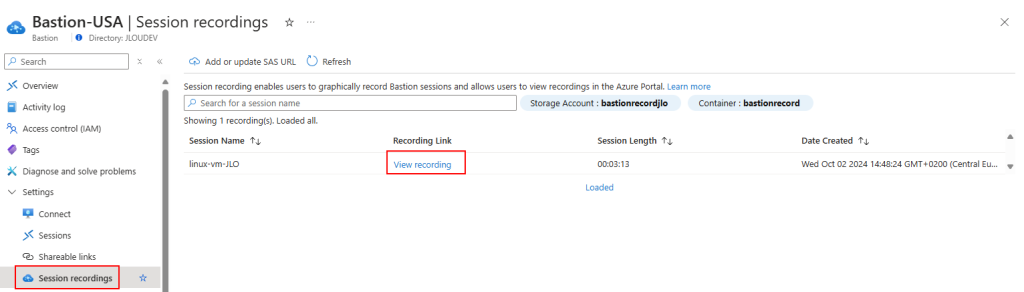
L’enregistrement s’ouvre dans un nouvel onglet avec une barre de lecture :
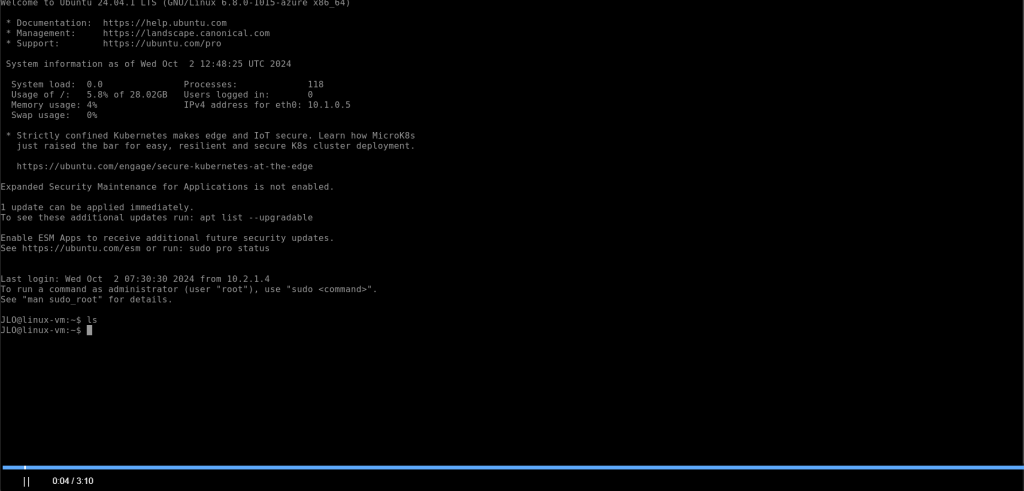
Testez un second enregistrement pour une session RDP :
Azure Bastion Privé
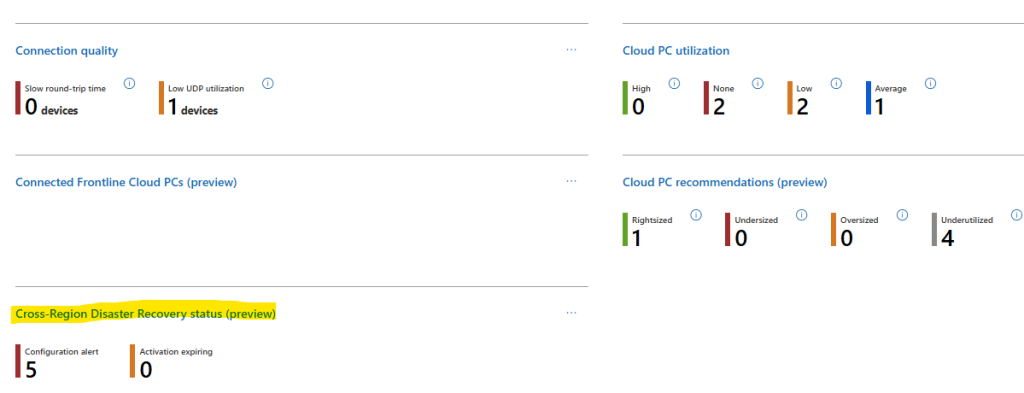
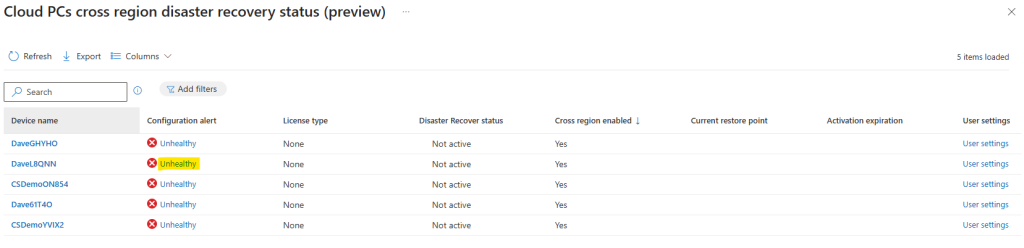
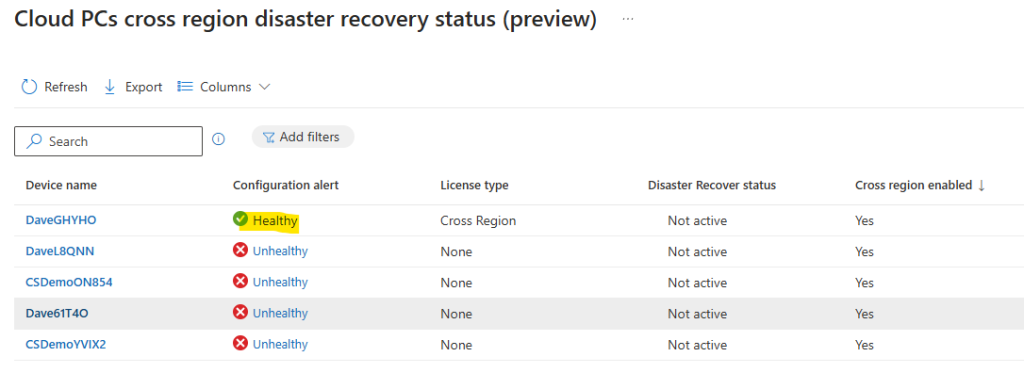
Note : La mise en place d’une connexion 100% privée pour Azure Bastion déjà en place n’est pas possible après coup :
Il est donc nécessaire de commencer par supprimer votre Bastion déjà en place :
Une fois votre Bastion supprimé, vous pouvez également supprimer son adresse IP publique :
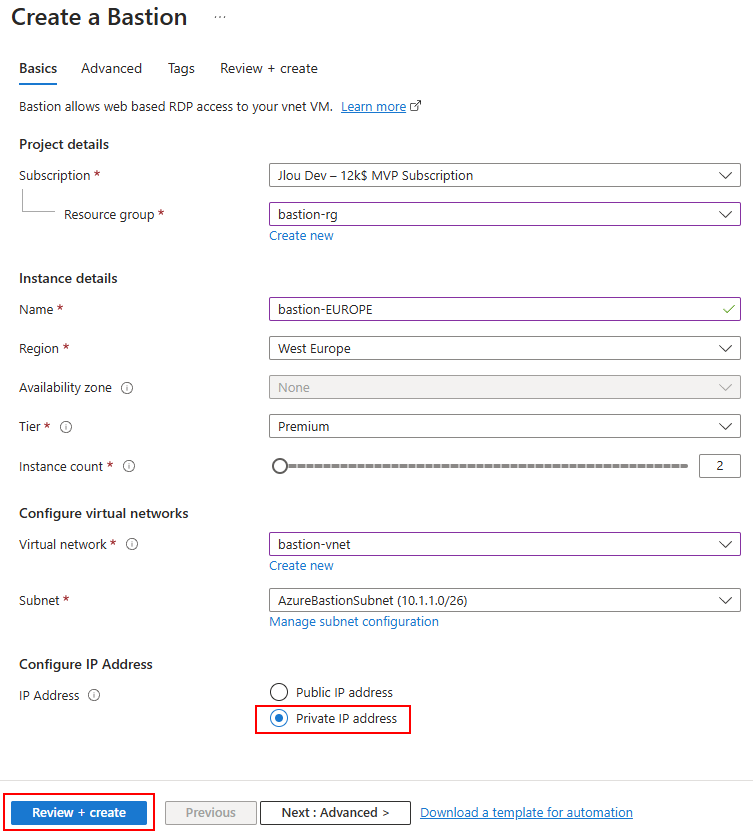
Le déploiement d’Azure Bastion en version privée se décide via la case à cocher suivante :
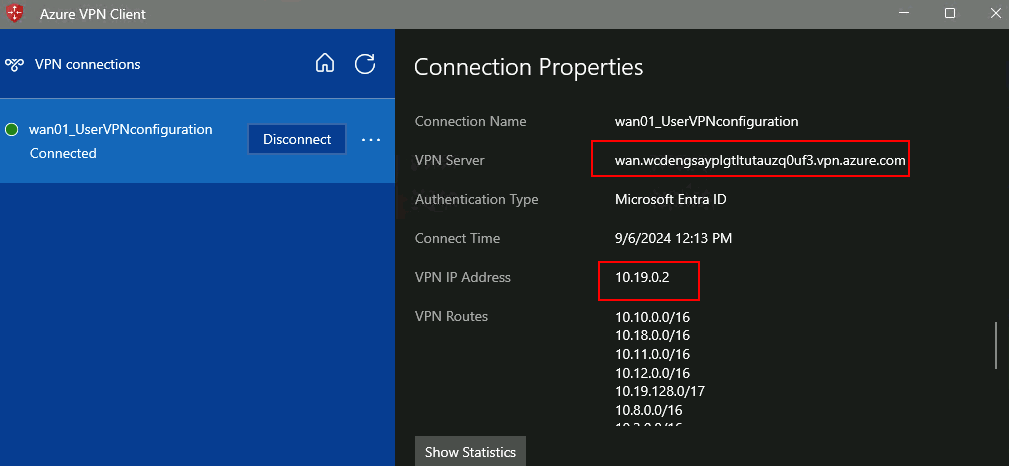
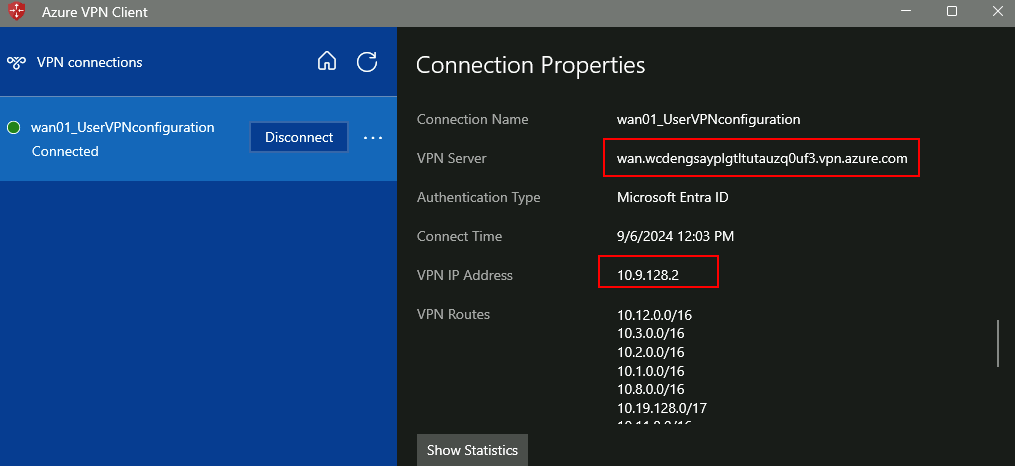
Une fois déployé, testez une connexion via cet Azure Bastion privé depuis un poste hors d’atteinte du réseau virtuel cible :
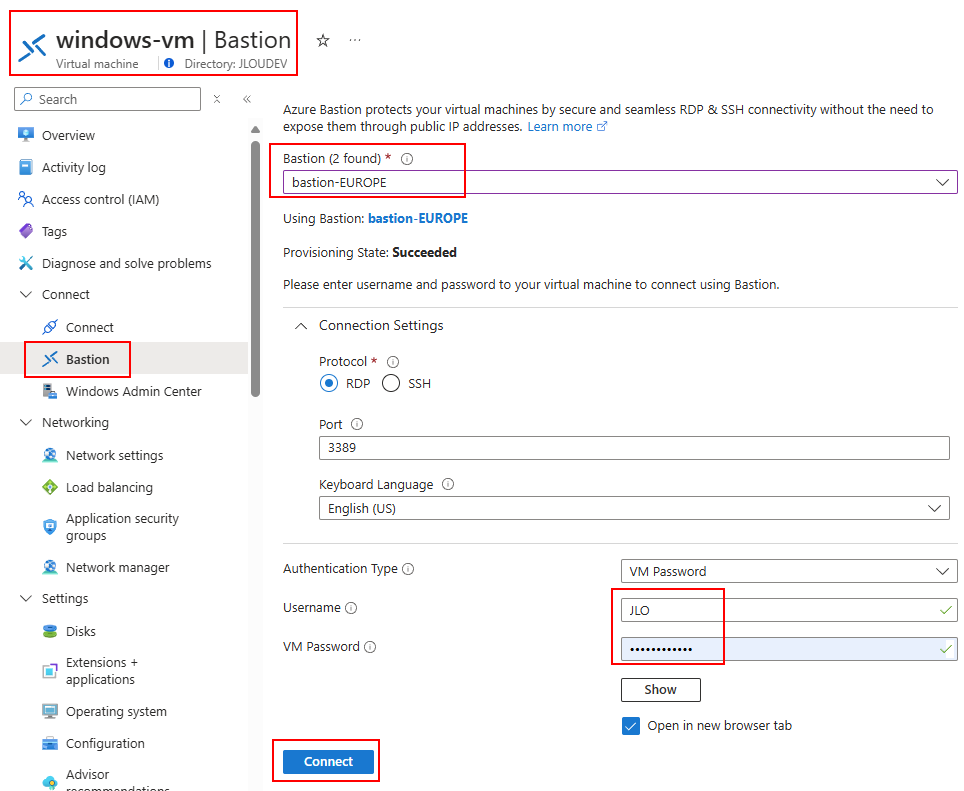
Constatez l’échec de cette tentative :
Afin de tester la connexion privée, j’ai créé un second Azure Bastion Standard sur un autre réseau virtuel appairé :
Puis j’ai activé la fonctionnalité lien partageable sur mon Bastion privé :
J’ai ensuite copié le lien partageable généré :
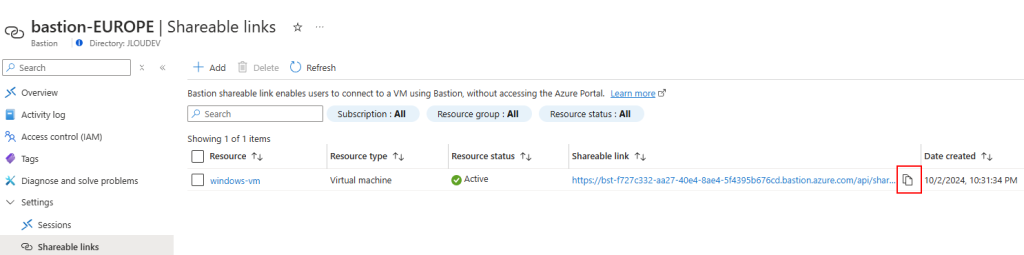
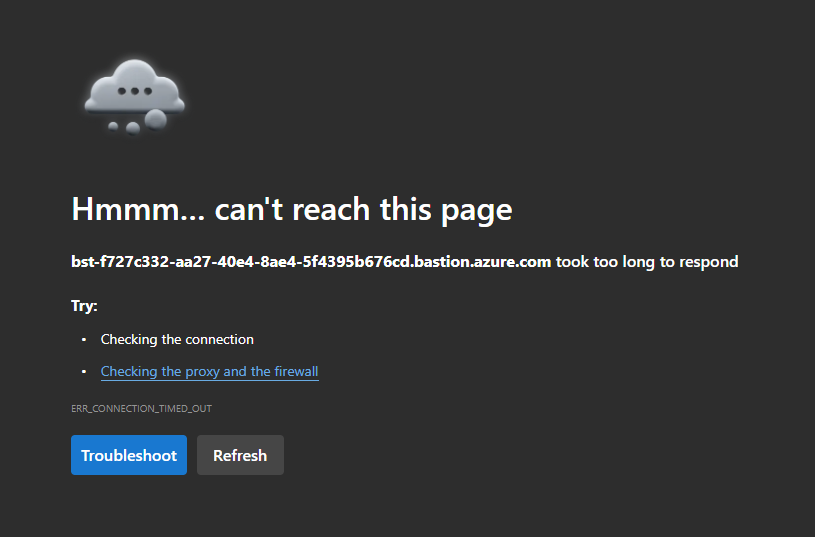
J’ai testé ce lien partageable privé, sans succès, sur mon poste local :
J’ai retesté avec succès ce même lien partageable privé depuis une session ouverte sur mon second Azure Bastion, dont le réseau virtuel est bien appairé à celui contenant mon Bastion privé :
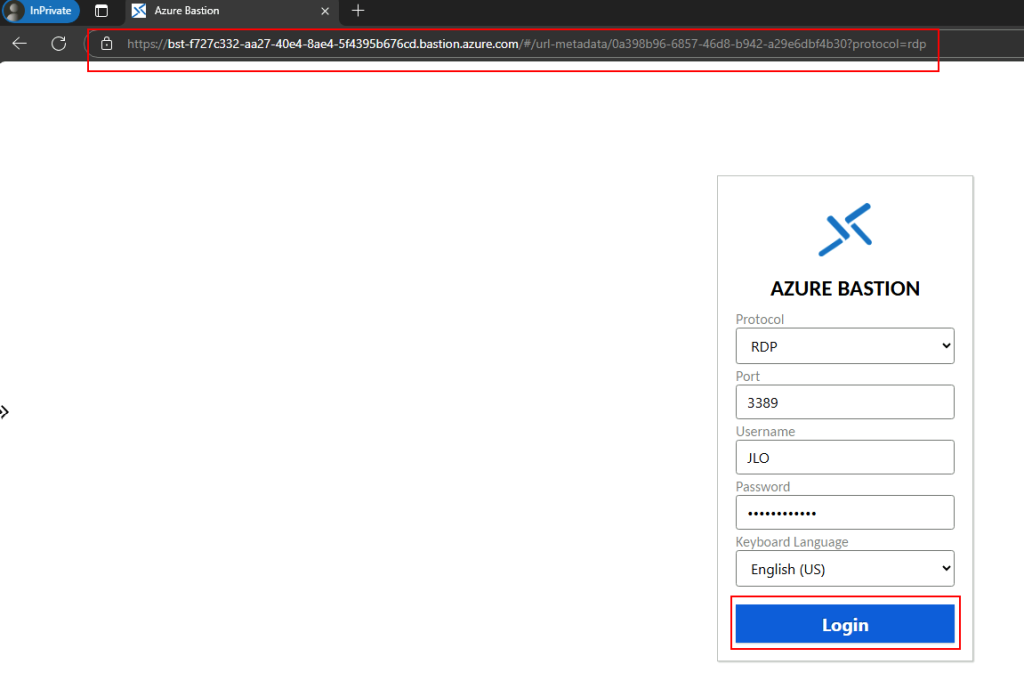
Via cette méthode, j’ai pu me connecter sans souci à ma machine virtuelle de façon 100% privée :

Conclusion
Sécurité et simplicité sont les adjectifs qui définissent très bien Azure Bastion. Azure Bastion permet d’accéder en toute sécurité aux machines virtuelles via RDP/SSH sans nécessiter d’adresse IP publique, ce qui réduit considérablement les risques d’exposition aux menaces comme l’analyse de ports et les exploits zéro-day.
De plus, il centralise le renforcement de la sécurité en une seule couche, éliminant ainsi la nécessité de sécuriser individuellement chaque machine virtuelle. La flexibilité offerte par les différentes architectures et références SKU permet de s’adapter à divers besoins opérationnels tout en garantissant une connectivité fluide et sécurisée, même dans des configurations réseau complexes comme l’appairage de réseaux virtuels.